I wrote this post not too long ago. But long enough ago that I completely forgot I wrote it. And then I put together these slides and video, and ended up saying many of the things I said back in 2021.
Read more here on data typing, date formats, preview windows, REST, & more.
Do you know what’s sad? An empty table, that’s really, really sad. So in this blog post, I’ll demonstrate batch loading CSV to Oracle…using ORDS and REST APIs for AUTOREST enabled TABLEs.
I have structure, but no data.
Create your Database
If you already have a database with ORDS, you can skip to the next section. But, I’m going to give you everything you need to get started from ZERO.
This will only take about 5 minutes if you don’t already have one. And I know you folks love the YouTubes. So here’s a new channel from someone you may recognize, our former and future intern, Layla!
It’s less than a 4 minute video, go watch, like, and subscribe!
Now, after you’ve created your database, you’re going to want a fresh, new application schema. DO NOT USE ADMIN.
Create a new USER
Users are basically synonymous with schemas in Oracle. Think of a schema as the collection objects owned by a USER. We’re going to create an EMPLOYEES table in a new schema, called HR.
Logged in as the ADMIN (or another DBA) user, we’re going to go to the Administration and Users section of SQL Developer Web.
Click on THIS box.
You can see your existing users, edit them (reset passwords!), and create new ones.Click THIS BUTTON.
Ok, now this next part is VERY important. We’re going to create a new user, and we want to make sure they can do the stuff we want them to be able to do, but nothing more. This is known as a minimal required privileges philosophy.
DO NOT FORGET TO GIVE YOUR NEW USER QUOTA ON THE DATA TABLESPACE.
Use a strong password, obviously.
DO NOT LEAVE THIS AS DEFAULT
You need the ‘Web Access’ so you can REST Enable the table. The EMPLOYEES table REST APIs will actually get executed using the HR user in the database.
Upper right corner, assign some QUOTA on the tablespace, which in Autonomous will almost ALWAYS be ‘DATA’. Our employees table only has like 100 rows in it, so ’25M’ is more than enough.
And that’s basically it, click ‘Create User.’
Now you could grant MORE roles, but we have ‘CONNECT’ and ‘RESOURCE’ selected out-of-the box.
Once the user has been created, you can now login as that user. Do that now.
On the USERS page, you’ll see your new user, and there’s a handy link you can use to get directly to their login page.
Click that ‘go’ button.
Creating our TABLE, REST Enable it
I’m going to test my account, make sure I can actually create objects AND store data in my schema.
Check and check!
Ok, onto our actual table, EMPLOYEES.
TABLE: EMPLOYEES (sans foreign keys and triggers)
CREATE TABLE EMPLOYEES(
EMPLOYEE_ID NUMBER(6,0),
FIRST_NAME VARCHAR2(20) ,
LAST_NAME VARCHAR2(25) CONSTRAINT EMP_LAST_NAME_NN NOT NULL ENABLE,
EMAIL VARCHAR2(25) CONSTRAINT EMP_EMAIL_NN NOT NULL ENABLE,
PHONE_NUMBER VARCHAR2(20) ,
HIRE_DATE DATE CONSTRAINT EMP_HIRE_DATE_NN NOT NULL ENABLE,
JOB_ID VARCHAR2(10) CONSTRAINT EMP_JOB_NN NOT NULL ENABLE,
SALARY NUMBER(8,2),
COMMISSION_PCT NUMBER(2,2),
MANAGER_ID NUMBER(6,0),
DEPARTMENT_ID NUMBER(4,0)
);
You can copy/paste this text into your SQL worksheet, and hit ctrl+enter to execute the code immediately.
Refresh your table list –
My table is there, and I can REST Enable it!
Signed in as the object owner (HR), I can simply right-click and REST Enable my table. Clicking ‘Ok’ would run this code (ORDS is our PL/SQL API for ORDS):
Note that I’m choosing NOT to alias the EMPLOYEES table on the URI. I however DO recommend you do just that. So switch P_OBJECT_ALIAS to something like ‘not_employees.’
On the REST Enable dialog, we also have the option to require AUTH. We want to ALWAYS say ‘Yes!’
Any request will need to be Authorized via this role or privilege.
Click ‘Enable!’
If that worked (it will!), you’ll see the tables list refresh with little connection plug next to it.
Right-click on the table, again.
I now have a cURL option! Click that!We try to make this easy for you, want ‘BATCH LOAD’ and you can pick your environment.
So, we’re good to go, we can load our table now, right?
ALMOST.
Our data (CSV)
We’re going to need some data, so you will you. I’ll share
A few important things, this needs to be CSV, with column headers. It’s easier if the strings are double-quoted. And our employees have a HIRE_DATE, defined as a DATE. So we’re going to need a DATE FORMAT we can use to tell ORDS what to expect when it sees those values. More on that in a few paragraphs.
You CAN deviate from those ‘rules,’ but if you do, you’ll need to use some of the optional parameters when calling the POST API on our EMPLOYEES table.
Are we ready to try?
Authentication & Authorization
We’re going to try to access the API now, but it’s not going to work. I want you to see what happens when we’re authenticated but not authorized.
Instead of using cURL (I hate it), let’s try a REST API client/GUI like Insomnia or Postman.
I’ve talked before here how we should be using the OAuth2 workflow to authenticate to our REST APIs vs using Database Authentication in Autonomous. But…we’ll keep it simpler here in this use case. And by simple, I mean Basic AUTH.
Using our HR username and password on the POST request, we get something perhaps a bit unexpected?
Whut, 401?
We’re authenticated, but NOT authorized. Our session doesn’t have the privilege required to access the REST API we published on our table. Remember we clicked the ‘protect’ switch when enabling the table, and it showed us a ROLE and PRIV? We need grant the privilege to the ‘SQL Developer’ role if we want to use database authentication.
To remedy that, head to the REST panel, then click on ‘Security’ and ‘Privileges.’
Find your privilege and click ‘the kebab button’ on the upper right-hand corner of the card, and select Edit.
Go ahead and give our Privilege a label and description.
The important part is up there where it says ‘Roles.’
We’re going to move ‘SQL Developer’ over to the Roles list for this privilege, and hit ‘Save.’
The ‘SQL Developer’ role is inherited by any Authenticated request that used database username and password. So once we have that, we won’t get the HTTP 401 (DENIED!) error.
Loading CSV to Oracle via REST. Look ma, no code!
You can basically just hit the ‘go’ button again now, but not quite. Remember we were talking about the DATE formats? Yeah, we need to account for that.
We’re going tell ORDS what our date format is in the CSV text file by using a parameter in the POST URI.
I have kids. Our family has had a family Netflix account since 2017. My daughter decided to jump into 18 Seasons of Grey’s Anatomy last year, and has been binging it ever since.
You request it from your online account. Do that in your browser, not on your Netflix app.
If you know where to look, it’s easy to find.
You’ll have to confirm the request. They say it will take up to 30 days. It took only 1 day for me.
Then you’ll get an email saying it’s ready. You’ll following the link, provide your password (again), and download a Zip file.
They provide A LOT of your personal data. From what I can tell, ALL of it. Kudos, Netflix!
We’re going to import that ‘ViewingActivity.csv’ file as a new table in an Oracle Database, so you’ll need one of those. I’ve talked about that before, a lot.
This will open a wizard, and on the 2nd page, you can define the columns. I’ve left the data type defaults, but have changed the precision of the text fields.
We’re going to treat these ‘duration’ bits of data as INTERVAL types, later.
Note that the wizard has recognized that ‘START_TIME’ is a date, and it’s recommending we bring it in as a TIMESTAMP, and has even recognized the proper format mask to read those values in.
We can click to the end of the wizard, and hit ‘Finish.’
When it’s done processing my 2.5MB of data, I can see it’s imported more than 14,000 rows. Is that sad? I don’t know, the four of us watch a TON of online content.
I simply added this data as a table called ‘NETFLIX’ –
It’s the entire history, not just the last 365 days that Spotify gave me for my request.
Step 2: Start doing SQL
Again, kudos to Netflix for including a ‘data dictionary’ in their personal data package. It’s quite nice –
I’ve highlighted the bits of data I’m going to need in my SQL to answer my ‘question.’
Profile – my daughter
Duration – how long did she spend watching it
Title – anything Grey’s Anatomy
Supplemental Video Type – just episodes, not teasers, trailers, bonus content, etc
Starting Simpler, what have I seen recently?
I know MY data, so let’s just make sure this CSV dump is accurate. So I’m going to ask what I’ve watched recently.
Yup, this sounds about right.
SELECT
START_TIME,
DURATION,
TITLE
FROM
NETFLIX
WHERE
PROFILE_NAME ='Jefferson'AND SUPPLEMENTAL_VIDEO_TYPE ISNULLORDERBY
START_TIME DESC
DURATION was brought in as a VARCHAR2, or a string. So doing MATHs on this column later will get a bit tricksy. However, the results seem ‘right’ to me. I gave up on re-watching the original Fletch about 30 minutes into it. I just wasn’t feeling it. So yeah, it looks good.
Let’s find my daughter’s ‘raw’ data for Grey’s
This is already really, really fun data. Disclaimer: this is totally a coincidence.
SELECT
START_TIME,
DURATION,
TITLE
FROM
NETFLIX
WHERE
PROFILE_NAME ='Daughter'AND SUPPLEMENTAL_VIDEO_TYPE ISNULLAND TITLE LIKE'Grey''s%';
The only tricky thing here is the TITLE predicate clause. Grey’s Anatomy has an apostrophe, and that’s also the character we use to enclose strings in Oracle SQL. So the ‘trick’ is you have to escape it. One way is to just use an extra quote.
This is very handy, especially when you have a mix of single and double quotes.
SELECT
START_TIME,
DURATION,
TITLE
FROM
NETFLIX
WHERE
PROFILE_NAME ='Daughter'AND SUPPLEMENTAL_VIDEO_TYPE ISNULLAND TITLE LIKE q'[Grey's Anatomy%]');
OK, now how do I sum up the duration?
That string is representing what Oracle basically considers an INTERVAL YEAR TO SECOND piece of data. Except in this case it’s only HOURS:MINUTES:SECONDS.
So what I’m going to do is create a VIRTUAL COLUMN that uses this data to create an actual INTERVAL interpretation of this data.
Let’s walk and chew some gum…add the VIRTUAL COLUMN and query the ‘new’ data.
We’re not physically storing new information here. VIRTUAL COLUMNs in an Oracle table allow for that data to be derived from other values in the row.
The TYPE of the new VIRTUAL COLUMN is ‘INTERVAL DAY TO SECOND.’ And the way it’s being derived is taking the value of the DURATION column and prefixing it with ’00 ‘
Then with that string being ‘computed’, I’m then sending that as an input to the TO_DSINTERVAL function, which returns an INTERVAL value.
Ok, so now I can just do a SUM on DURATION_INTERVAL, right?
Well, not quite. Unfortunately the database doesn’t give us a SUM() function for the INTERVAL type. So we need to do something else.
From the INTERVAL value, we’re going to extract the total number of minutes. And from that value, we’re going to total that up, and divide by ’60’ to get the total number of hours.
So, ~ 200 hours, 20 minutes.
I asked my wife, does that sound about right? And yes, about 8 straight days of binging over the last 18 months sounded about right.
Ok, let’s look at that code, esp the the SELECT
-- Hours spent watching Grey's AnatomySELECTSUM(EXTRACT(MINUTEFROM duration_interval))/60 time_wasted
--title, duration_intervalFROM
NETFLIX
WHERE
PROFILE_NAME ='Daughter'AND SUPPLEMENTAL_VIDEO_TYPE ISNULLAND TITLE LIKE'Grey''s%';
It’s always easier to break the nested function calls into the various pieces, so let’s do that.
extract(minute from duration_interval) – pull out the minutes portion of time
sum sum(extract…) – add this number up
/60 – take the sum and divide to get ‘hours’
Wait a second, those pesky seconds really add up, right?
Now, simply writing this post and the description has forced me into a different level of thinking. What about the SECONDS? Over 666 viewings, surely the fractional number of minutes will be significant?
Let’s find out.
Crap, that’s an EXTRA 5 hours.
So if I ignored the seconds, I’d be off ~2.5% in my answer. Is that significant to worry about? Probably not. But you need to KNOW what you’re asking, when you’re writing the SQL. Assumptions DIG HUGE HOLES that you might have to crawl out of later.
So to answer my original question, my daughter has spent ~ 205 hours watching Grey’s Anatomy since May 22nd, 2022.
Kudos to my fellow product managers here on the Database team at Oracle. They helped me a bit with this SQL, especially Michelle with the Extract function().
Disclaimer: I’ve probably spent at least 50 hours watching this show with her. Enough to know the writing got EXTREMELY lazy when it came to killing off the main cast of characters.
Disclaimer2: if you’re going to leave a nasty comment about my kid’s taste in pop culture entertainment or my parenting skills, just don’t. Feel free to bash my data modeling and SQL skills, as always.
But this post is more about the janitorial work one does AFTER your data loading tasks have been completed.
When loading data to your tables, we take advantage of a database feature provided via DBMS_ERRLOG (Docs.) This allows us to LOG any failed rows to be inserted to your tables. The error log tables all start with SDW$ERR$_.
You’ll have one of these logging tables for each table that’s had data imported using SQL Developer Web.
Let’s import some data
Need some interesting data to play with? Maybe you should try your own! I’ve talked about this a lot, but otherwise I’ll assume you have no shortage of CSV and Excel files laying around that you might want to put SQL over.
More fun examples, using your own data to learn SQL, build REST APIs, etc.
In the right hand corner of the Worksheet, you’ll see the ‘Data Load’ button.
I’ve added 4 or 5 files and hit the ‘Run All’ button.
Once it’s finished, I can see some new tables! Let’s go browse one.
Woohoo, my music is here.
If I go to query one of the SDW$ERR$_ tables, I can see there weren’t really any failed inserted rows.
I’m happy about this.
Ok, my data is imported, I don’t need these logging tables anymore.
Let’s filter our list of tables, and I guess start dropping them.
No need type these out!
Yes, I could write a script, or even create a JOB to drop these tables on a regular basis, or I could just ‘click the button.’
Using the Data Loading dialog to drop our error logging tables
Let’s re-open the data loading dialog, this time from the table browser.
There’s a ‘History’ item.
Yeah, that’s what we want, the History.
Clicking into that brings me into this screen, pay attention to the toolbar, there’s a ‘trashcan’ button.
This does what we want.
Clicking that button we get a warning –
Yeah, yeah, yeah – nuke them already.
The action can’t be reverted because not only do we DROP the tables, we drop them with the PURGE keyword. That means they won’t be available for recovery from the Recycle Bin.
My history is gone, and so are all of my accompanying SDW$ error tables.
This button saved me a lot of typing. I figure you might be loading data too on a regular basis, and if you want to clean up your system, this will come in handy!
But I’ve found it’s necessary to tell a story multiple times, in multiple ways in order to really get the word out. And this is a HANDY feature.
What it does
REPEAT X Y
Whatever the last thing (a SQL statement, or even sa SQL script!) you executed…it executes again, X number of times, with a Y second delay.
The delay Y max is 120 seconds.
And in between executions, it refreshes the screen. Which makes it work quite nicely as a custom ‘monitor.’
Now let’s put this in terms that are interesting to YOU.
What it is, that you do here
You load data. All the time. And you like to keep an eye on how that’s going. So let’s setup a scenario where we’re going to load some CSV to an Oracle table.
And while that data load is going, I want a ‘monitor’ on my CLI to show me what’s happening.
And the cool part is, we can use the REPEAT command to run both of those things.
I have a script, “repeat-multiple.sql” that looks like this –
WITH metrics AS(SELECT statistic# AS id
, name
,VALUEFROM v$sysstat
WHERE class =1AND( name LIKE'user %'))SELECT STAT_6.value AS USER_COMMITS
, STAT_7.value AS USER_ROLLBACKS
, STAT_8.value AS USER_CALLS
, STAT_12.value AS CUMULATIVE_USER_LOGONS
, STAT_13.value AS CUMULATIVE_USER_LOGOUTS
, STAT_26.value AS USER_IO_WAIT_TIME
FROM(SELECTMIN(VALUE)ASVALUEFROM metrics
WHERE name ='user commits') STAT_6
,(SELECTMIN(VALUE)ASVALUEFROM metrics
WHERE name ='user rollbacks') STAT_7
,(SELECTMIN(VALUE)ASVALUEFROM metrics
WHERE name ='user calls') STAT_8
,(SELECTMIN(VALUE)ASVALUEFROM metrics
WHERE name ='user logons cumulative') STAT_12
,(SELECTMIN(VALUE)ASVALUEFROM metrics
WHERE name ='user logouts cumulative') STAT_13
,(SELECTMIN(VALUE)ASVALUEFROM metrics
WHERE name ='user I/O wait time') STAT_26;
SELECT systimestamp;
SELECTCOUNT(*) NUM_BANK_TRANSFERS FROM bank_transfers;
Show me some session stats, show me what time it is, and show me how many rows are in my BANK_TRANSFERS table.
Let’s go!
Terminal one…run the load command. Not once, but 15x, with a 1 second delay.
And then I follow that with the repeat command, “repeat 15 1”
5001 rows for each batch. 75,015 rows loaded in total – thanks Chris for the maths help.
Terminal two, watching what’s happening over in terminal one.
I run the @script and then follow that with another “repeat 10 1”
Look at it go!
What did we learn today?
The REPEAT and LOAD commands are quite handy, AND can be used together! Also, if I go more than a few days without blogging, I start to get itchy. I should probably see a doctor about that.
This question popped twice in the last few days, and that’s always a prompt for me to put together a blog post AND sort our product docs. Here is that blog post.
But first, the question –
Can we use relative paths in our changeSets?
Customers A & B
Yes! Let’s look at an example.
In my scenario I’m running SQLcl, interactively, and I’m going to process 3 changeSets, that will:
create a table, CSVS
load said table with the SQLcl LOAD command
print the current working directory from inside the SQLcl script runner
Our controller changeLog will use relative paths.
The changeSet in step 2 will use a relative path for the location of the CSV file.
My SQLcl runtime CWD will be the rel-paths-load directory, home of the controller.xml
So I can simply run –
lb update -changelog-file controller.xml
The output
That directory listing/path gets important in a few paragraphs.
We can also see in there feedback like
'Running Changeset: dirA/table-load.xml'
That’s using the relative file path location as referenced in the controller, it’s in a subdirectory, under the controller in dirA.
The table1-load changeSet, using SQLcl’s LOAD command
But let’s do a fresh take. In the previous example, I used the ‘cd’ command in my changeSet to tell SQLcl where to look, but maybe you want to use relative paths in SQLcl’s script engine as well.
The scriptrunner process that kicks off to handle the runOracleScript changeSet adopts the current working directory from where SQLcl was kicked off. I’m starting SQLcl from where it’s installed,
c:\sqlcl\23.3\sqlcl\bin
So when I want to reference the location of my CSV file in dirB, the relative path gets a bit fun. For debugging/testing, I created another changeSet that simply printed for me the CWD from inside the scriptrunner –
Yeah, I’m just doing a !dir to see where I’m at (in Windows CMD speak.) And here’s a callback from the output I showed at the beginning, seeing where the SQLcl scriptrunner path is set to…
Hence the ../../../../ to get back to C:\
Don’t forget the -search-path option for the lb update cmd
Instead of starting off with a ‘cd C:\Users\JDSMITH\Desktop\lb\rel-paths-load’ in my interactive SQLcl shell session, I can use the -search-path directive (Liquibase Docs) to tell Liquibase where to look for files.
There can be lots of typing when you’re working in interactive mode. We’re in the process of setting up tab-completion for all of the commands in SQLcl, and 23.4 will have it ready for the liquibase (lb) commands.
We’re still working on this, sorry for the YELLING, we’ll get that sorted for the release.
The 23.4 update also includes more than 15 bug fixes for the Liquibase feature, and we will have that ready in time for the Winter holiday break.
The changeLog is interesting, even for a ‘dot 1’ release. We have few nice new features for you!
Export to Clipboard, vs file
On the destination, simply toggle from File to Clipboard, and you’re good to go.
Browsing a package spec, but want the body?
Just right-click!
Dedicated Connections per Worksheet
If I open 5 SQL worksheets on a database connection, you’ll end up with 5 separate connections to the database. This means you can have multiple, long running tasks going concurrently.
It also means you can be much more productive, or consume many more resources than you could before. We suggest closing worksheets when you’re doing doing work, to free up the server resources. This isn’t new advice, we offer the same for our other tools like SQL Developer.
You can also disable this feature and return to the pre-24.1.1 behavior, switch Sessions per attached worksheet to ‘off.’
There’s more, much more…
Thanks again to all the community users who shared their feedback. Many of these items came directly from y’alls.
Like this bug fix…
“Duplicated table aliases showing in autocomplete”
previously the X. got duplicated to x.x.commission_pct –
50k more thank you’s
We got to 50,000+ installs! Now let’s see how fast we can get to 100,000 and 1,000,000!
You can now see your Connection Names in the Status Bar!
The statusbar at the bottom, is showing my line#:curpos | connected user | connection name | editor mode | pending transactions | last query execution time.
Most of the work done over the past 3 months was spent optimizing the projects feature we released in 24.3.
A person in the APEX community wrote this post, but it 100% applies to developers working on projects that are NOT APEX, as well! It’s a good read if you want a break from me!
I’ll just tease the feature here, but this is definitely the easiest we’ve ever made it to work with an Oracle Database development project, where you need to manage the code behind your database objects and PL/SQL programs.
I can create a new project, whose database objects occupy one or more schemas, and we’ll set everything up for you.
And then you’ll have a source and dist set of folders where you can both maintain easy tracking of differences for the objects as you developer them (src), AND build a deployment script that would take you from v1, to v2, to v3 (dist).
What your local file system will look like now –
We use the existing Liquibase support in SQLcl and in your database where you have deployed projects to manage versioning and to provide reporting of who applied what, where, and when.
This release adds support for Excel files via the LOAD command, in addition to the existing CSV loader.
And the previous release, 24.3, added support migrating your Access MDBs (I won’t call them databases, but they’re kinda databases).
Let’s take a quick look at both.
Access
The command you want to look at is ‘mdb’ – the help will give you the rest.
mdb list -file /path/to/access.mdb file
Then we can choose to copy 1 or all of the tables.
mdb copy -file /path/to/file -table table_name
Excel
I’ve talked quite a bit about the LOAD feature, so you’ll want to take a look the Docs to get a feel for how it works.
The first thing you need to do is set the ‘loadformat’ parameter such that the load command will know to expect incoming Excel, either xlsx or xls.
Surprise, the random export contained data from my EMPLOYEES table.
So what I actually ran was:
SQL
--switch directory to LOAD can see/find my excel filescd /users/thatjeffsmith/documents--set load settings to 'xlsx' modeset loadformat xlsx--load the data, to a NEW table, called RANDOM_TABLEload random table export.xlsx new
The SET LOADFORMAT and LOAD commands have a ton of settings and accompanying HELP.
Note that if your excel file has columns formatted as dates, we’re bringing them over as VARCHAR2s, but this will be addressed shortly.
and most likely by doing the thing I read about in a blog
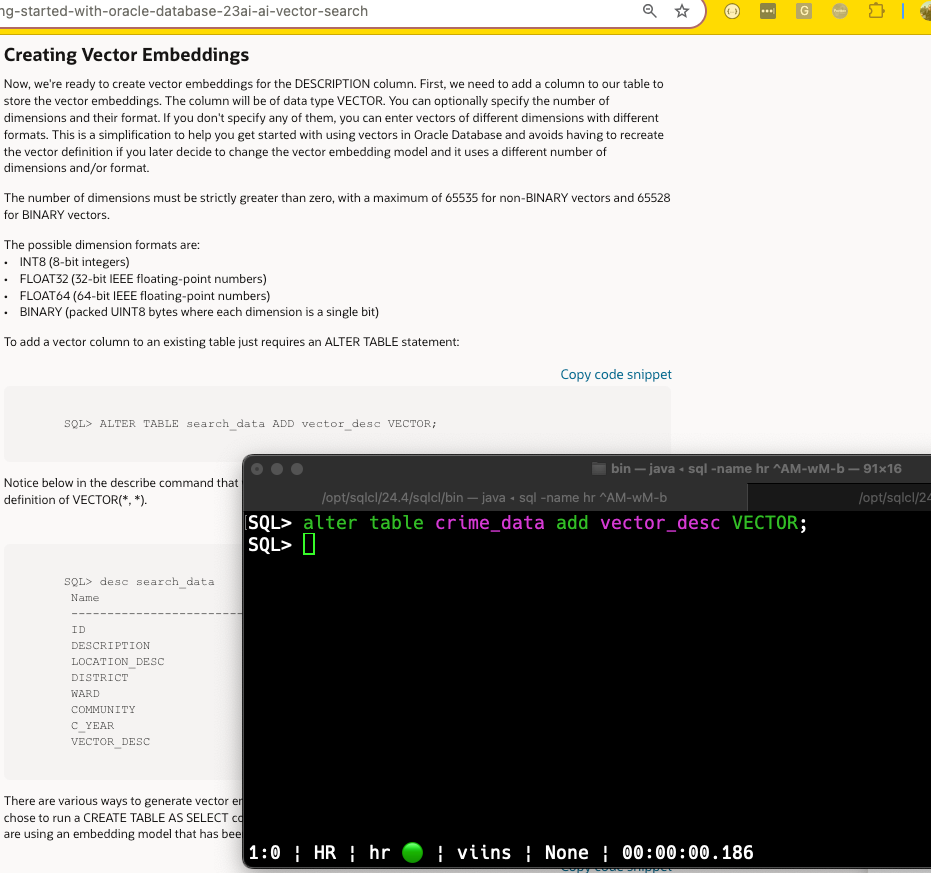
I’ve been trying to keep up with AI Vector Search in 23ai (yes, I am but a mere human), and one of the new concepts to me, is Hierarchical Navigable Small World (HNSW) Indexes.
I’m hoping to be able to understand better what my execution plans are telling me when I start comparing vectors using these new types of indexes, for example –
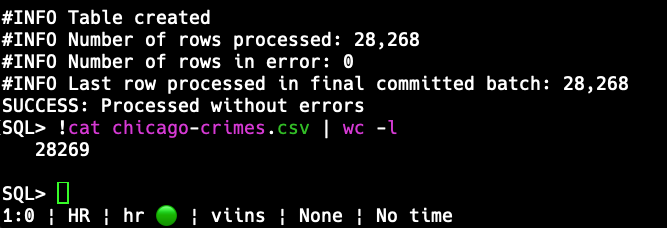
Andy’s HNSW post is using this data set, let’s load it!
Chicago’s Data Portal has a Crimes 2001-Present data set, and I’m going to download the CSV version of that.
Once it’s downloaded, here’s the general take I do.
Spark up SQLcl, use the LOAD command to generate some DDL
I’m going to use the ‘CD’ command to jump to my downloads folder, and then I’m going to use the LOAD command with the ‘SHOW’ keyword to just ‘show me’ what the LOAD command would do with this new CSV data if it were to be turned into a table.
Note I’ve done zero setup, this is just my ‘hey, maybe this will be good enough, attempt.’
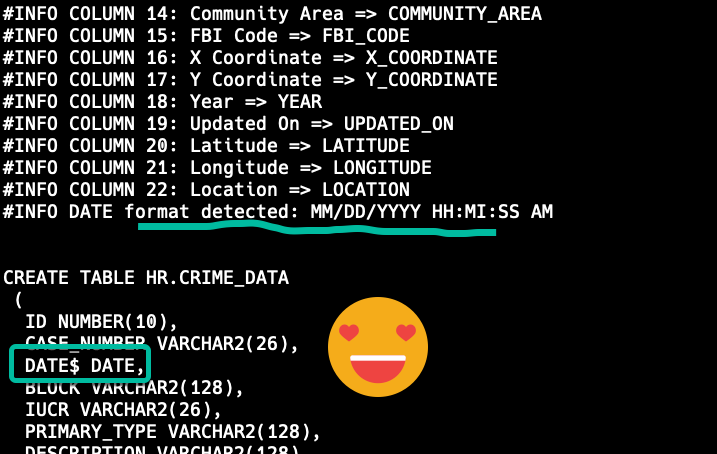
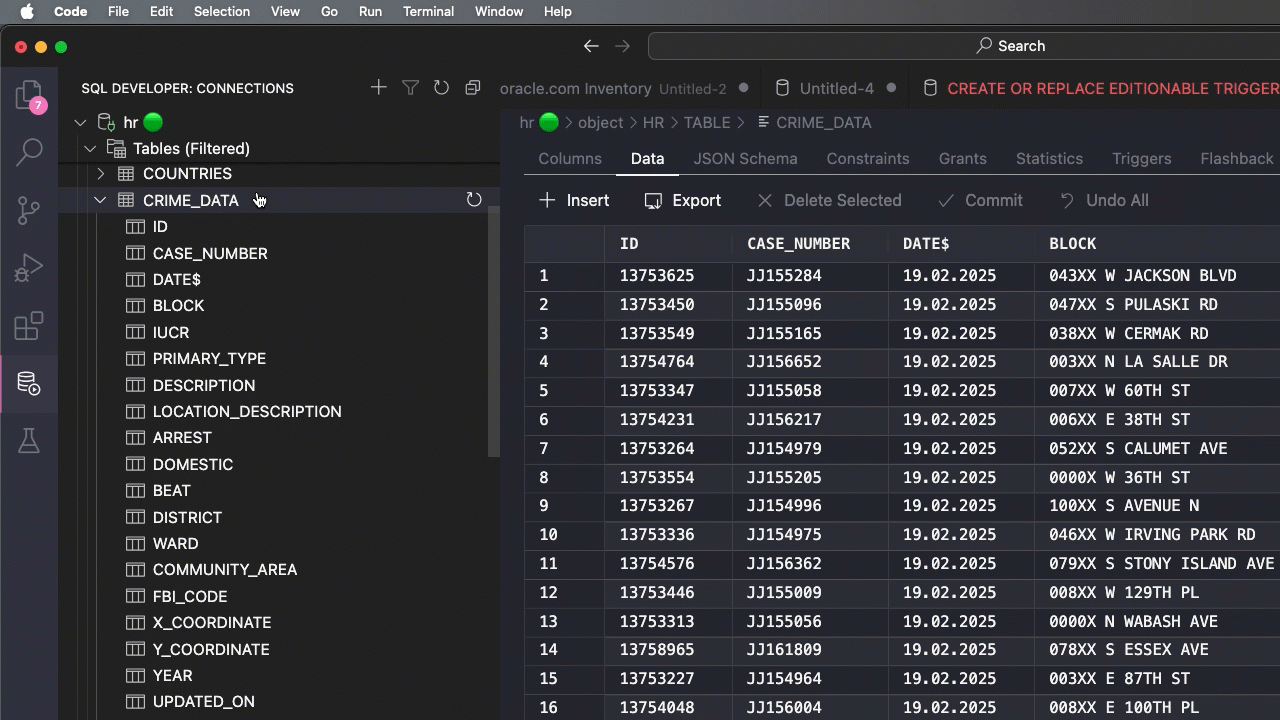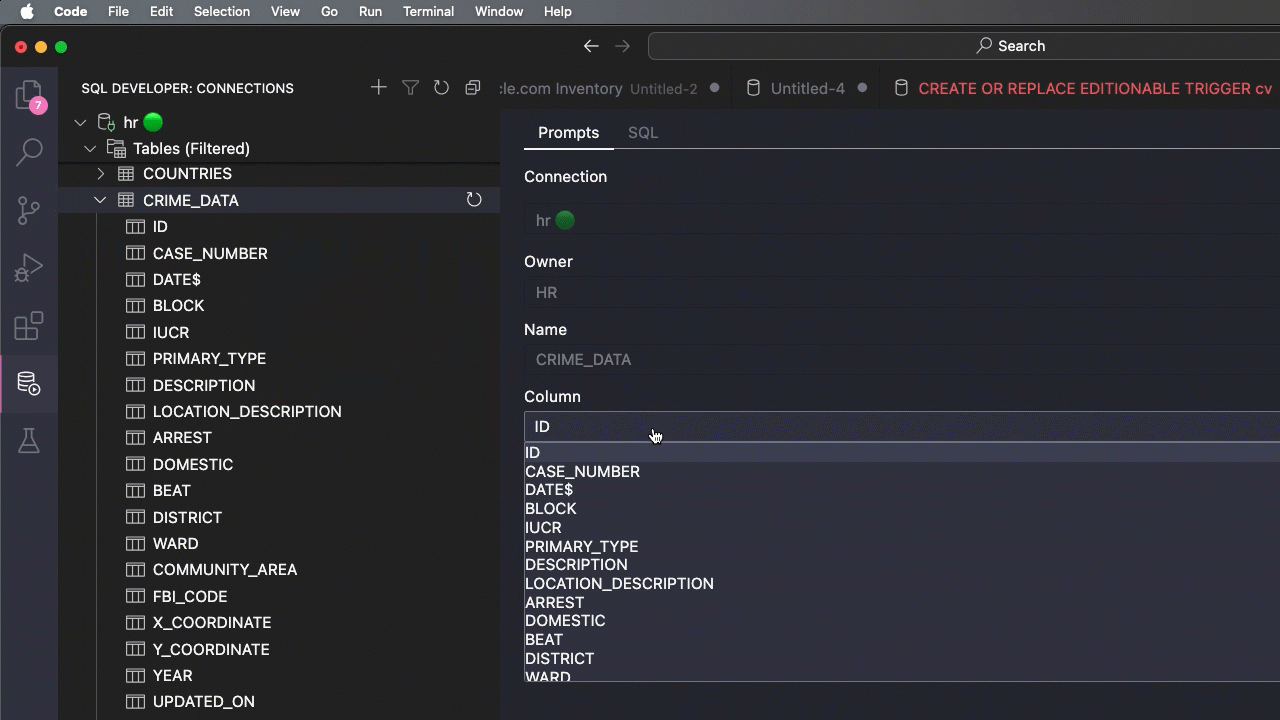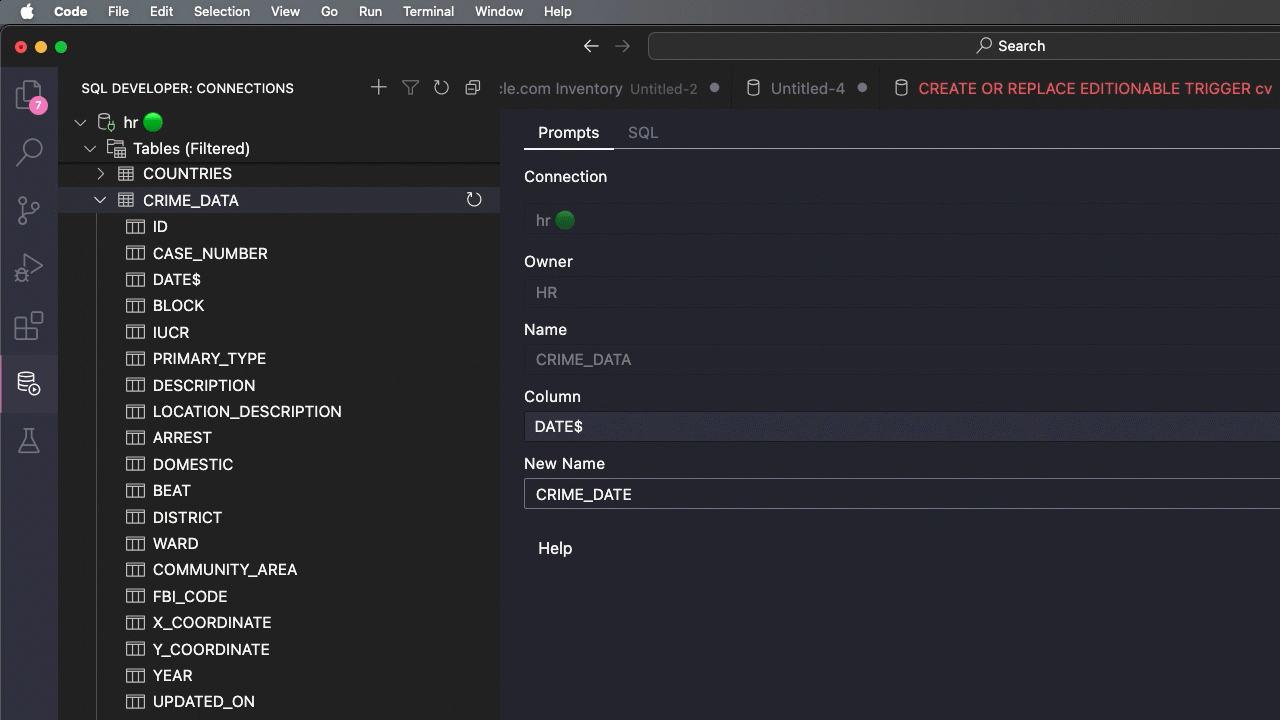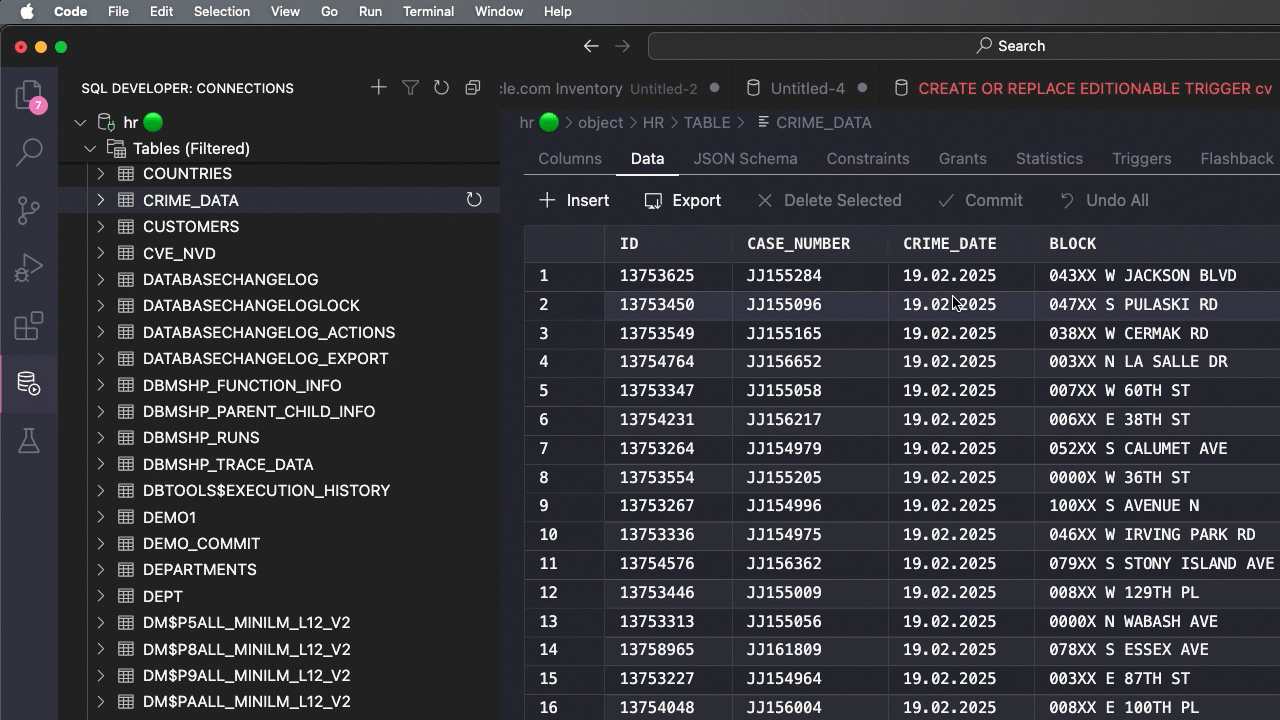
Why is this a red flag? You will wanting to query those dates as dates, and to do so you’ll need to use a function to convert them, that’s both ugly and slow(er) than if it were just stored as it should be, a DATE.
To fix this, we need to tell the LOAD command what date format to expect when streaming the data through from the file to the table.
Let’s ‘peek’ at the data
Alright, now I know how Chicago’s data portal is choosing to communicate when a crime has happened, now I need to tell SQLcl that.
show load and set load
‘show load’ will tell me what the current settings are for doing a LOAD job.