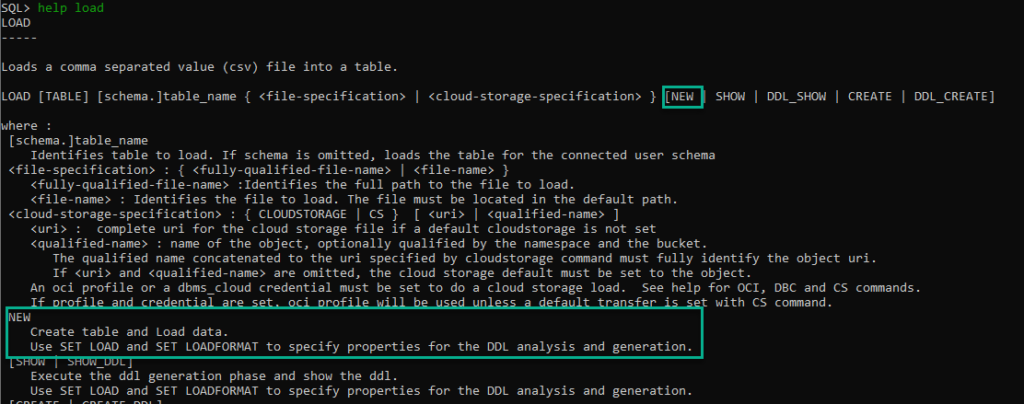
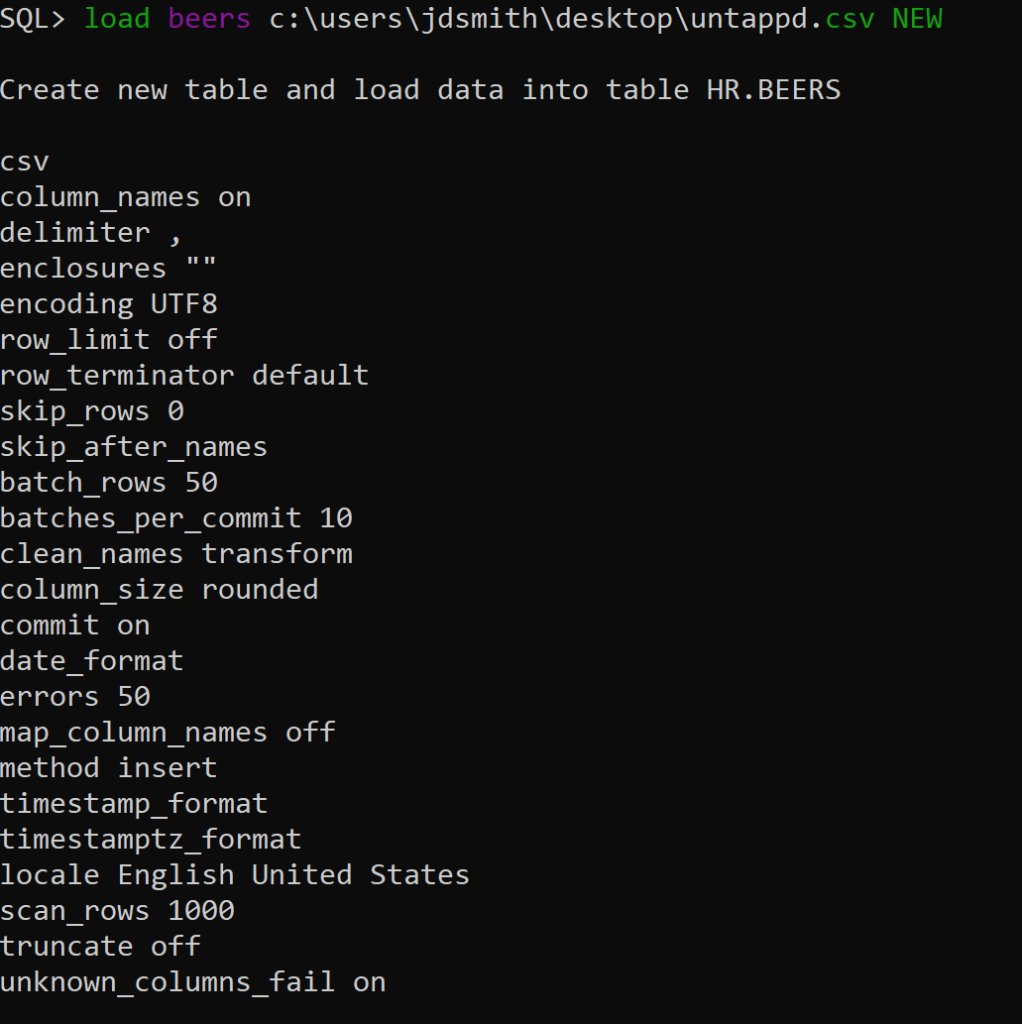
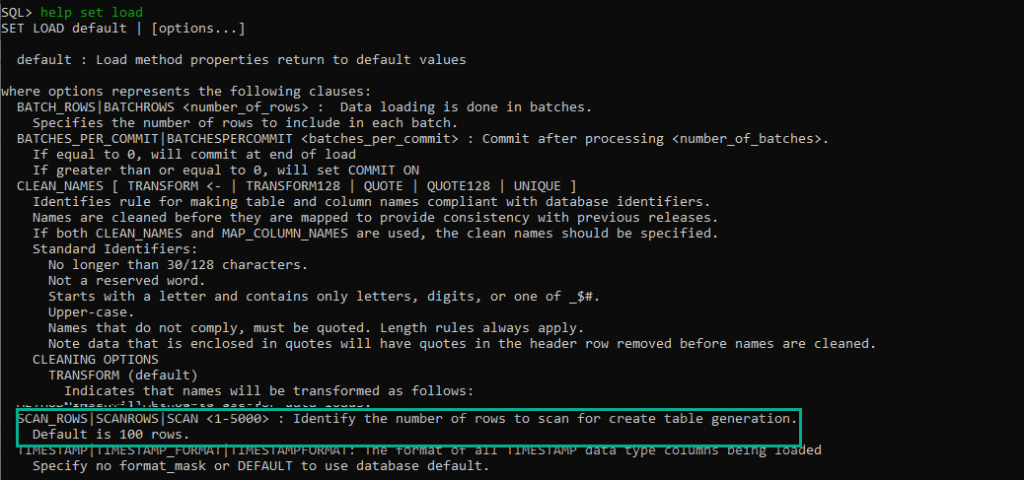
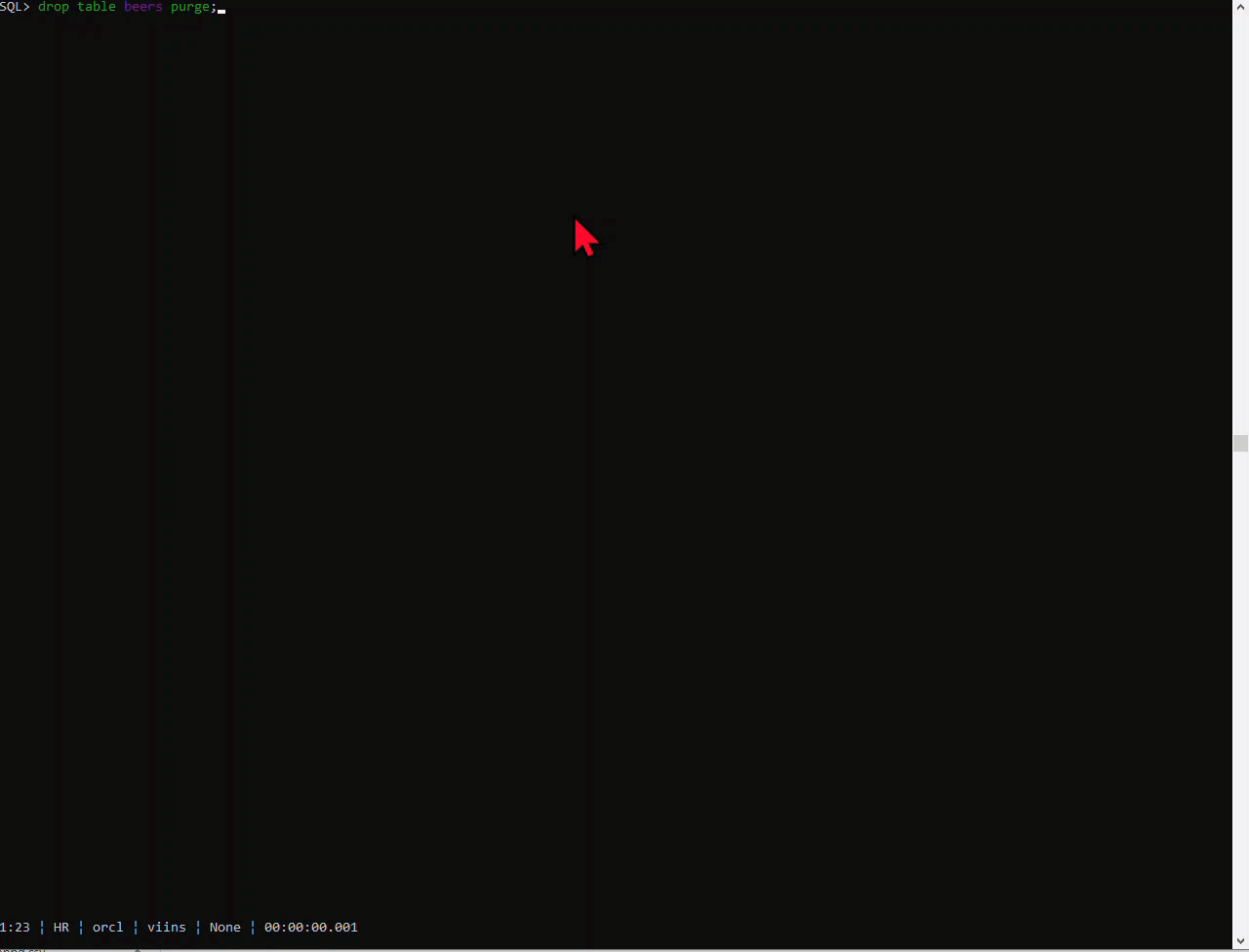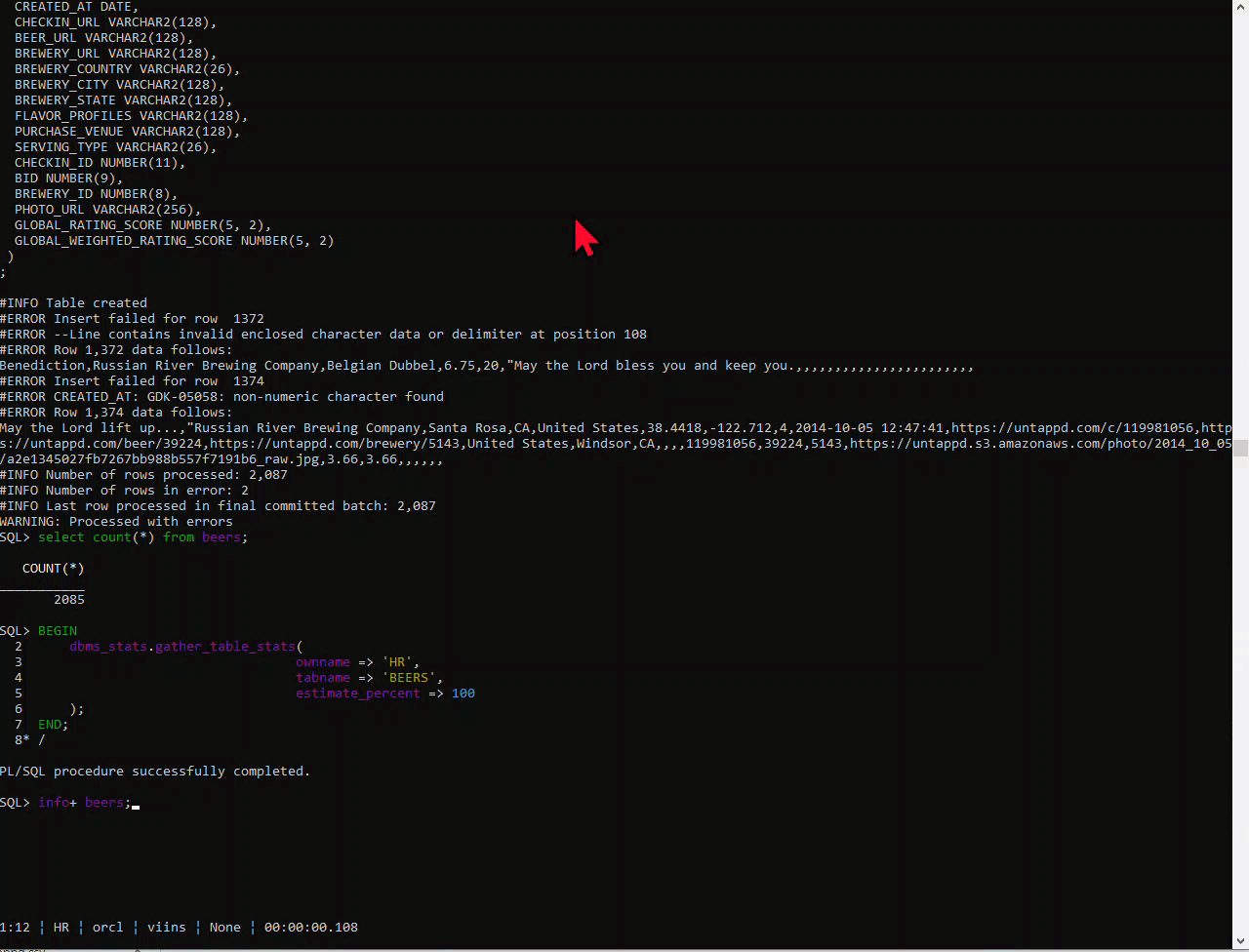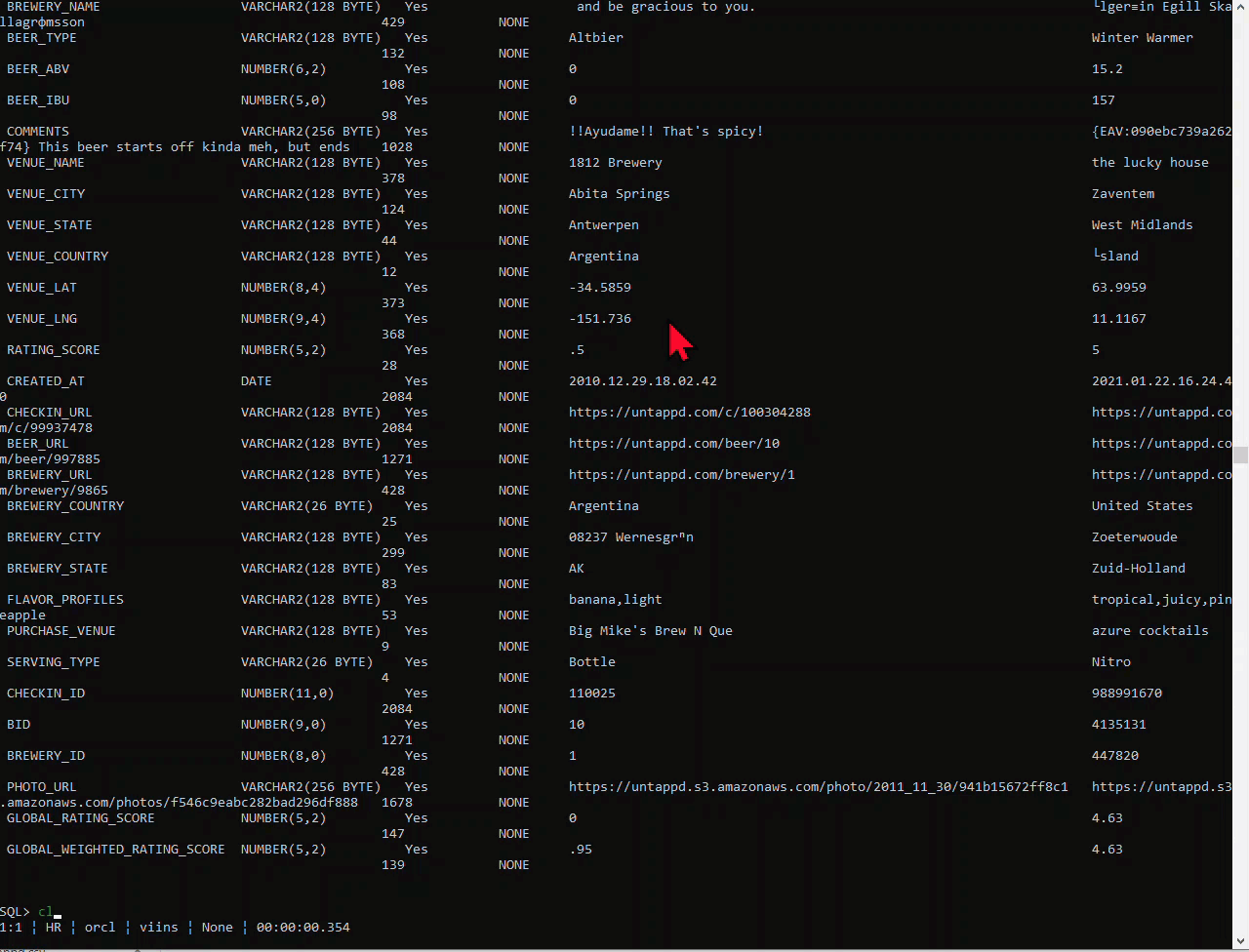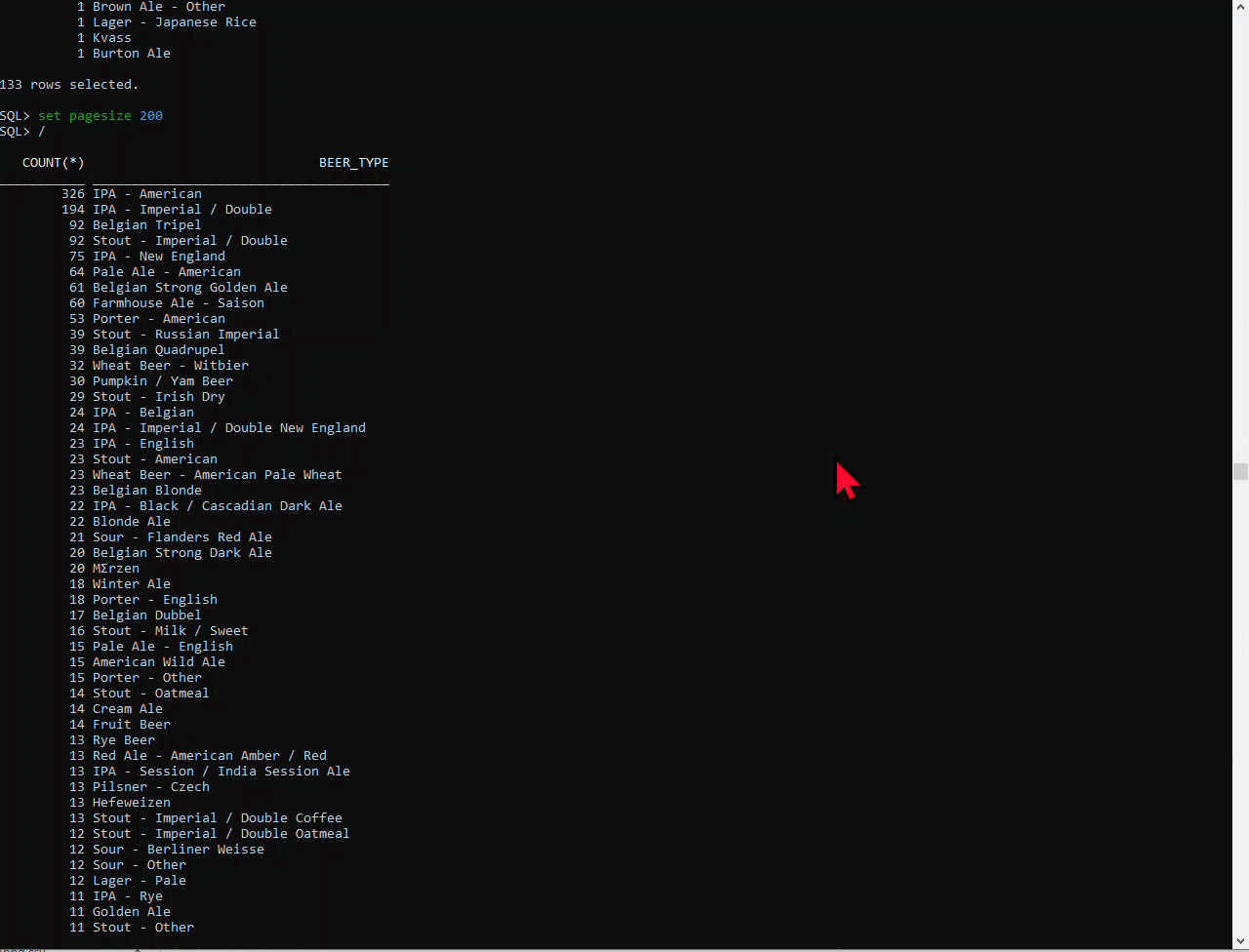
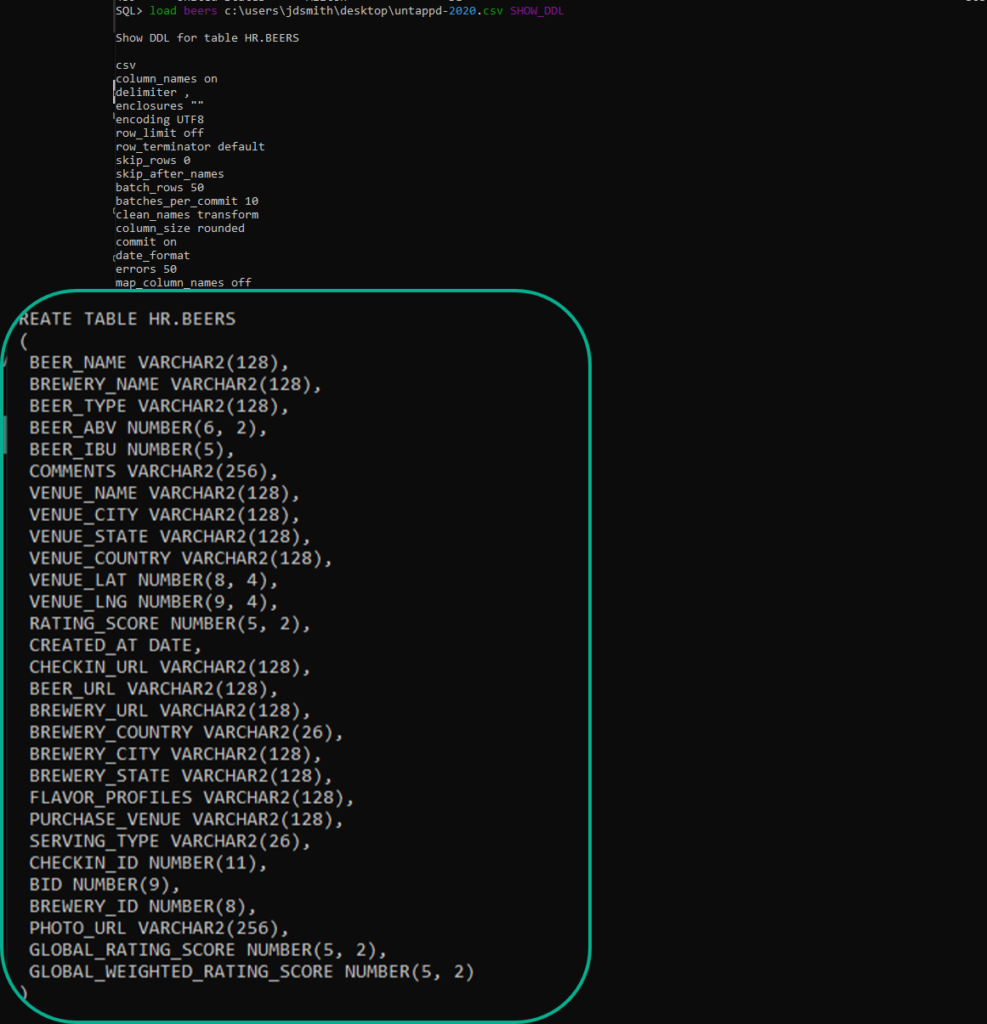
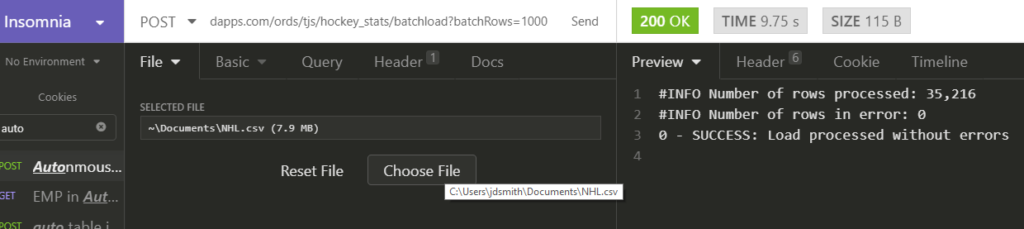
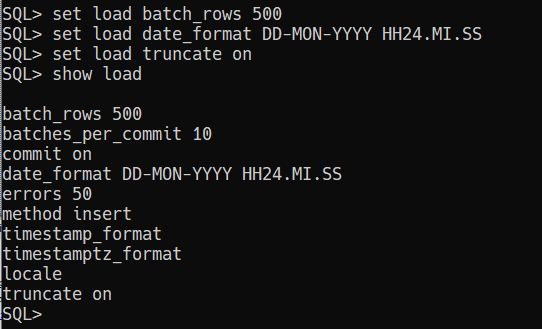
I find that programs that are developed by the same folks that use that program in production are some of the best applications out there. The developer is the user. They have to eat their own dog food – an unpleasant metaphor, but one that’s pretty well understood. Two great examples of that here are APEX and of course SQL Developer.
Of course not every dog gets to add his own secret ingredients to his dinner!
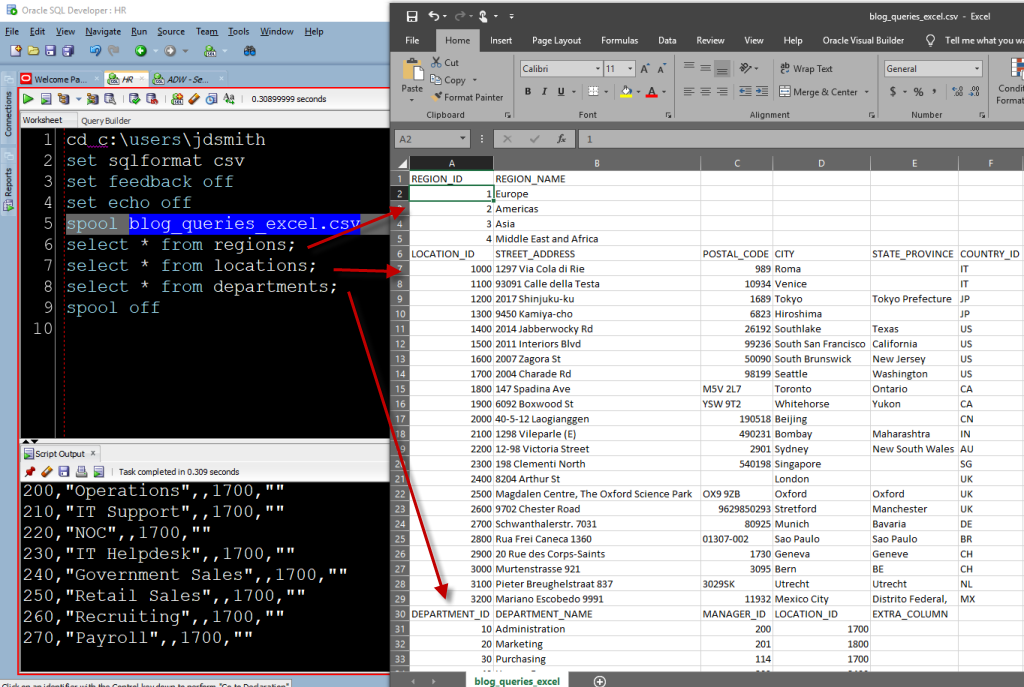
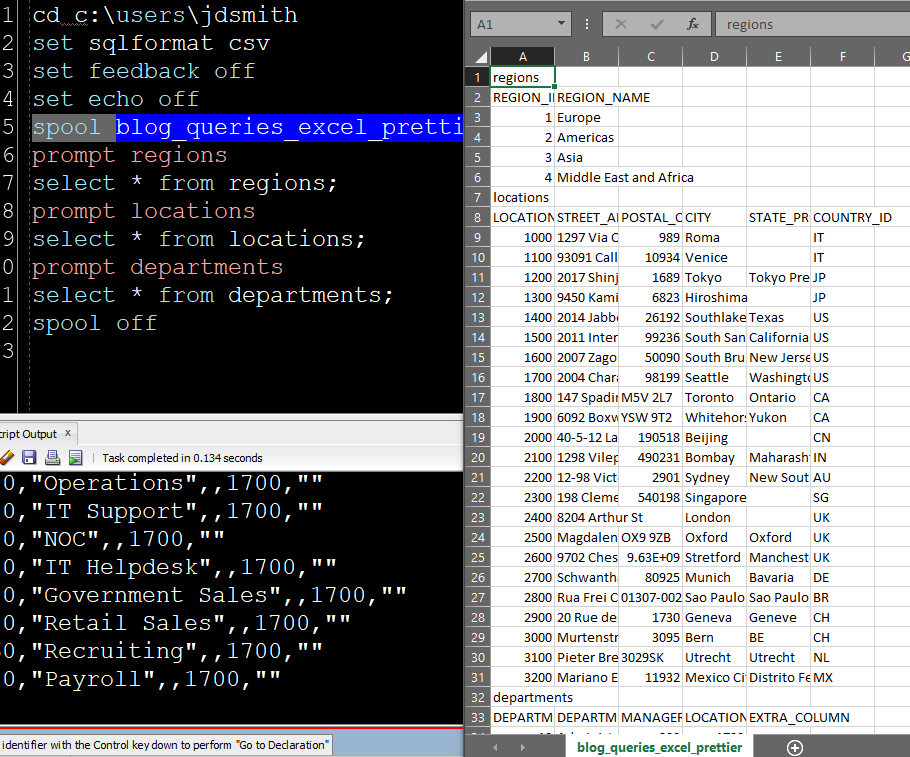
I also find that lazy developers make the best developers. They are so lazy that they will spend a few extra minutes to write a program that writes their programs for them. And so you’ll find this cool kind of stuff all over the application.
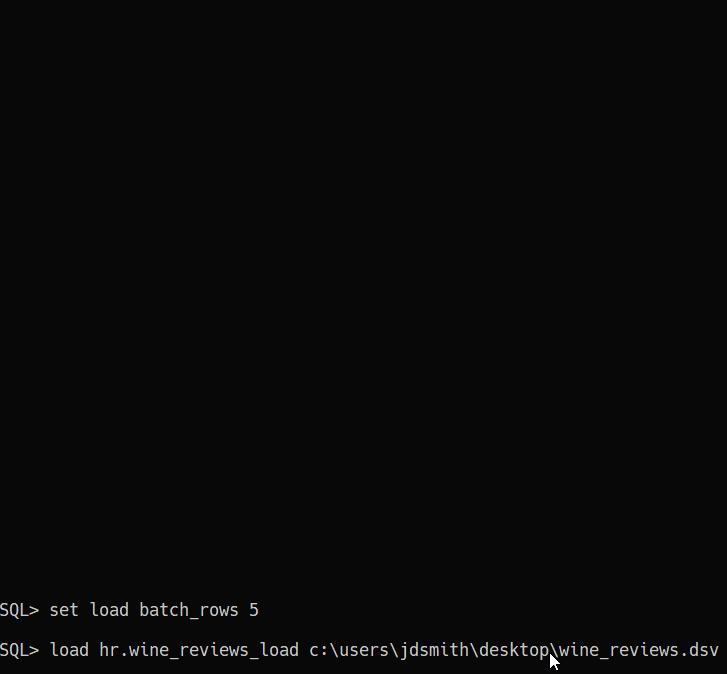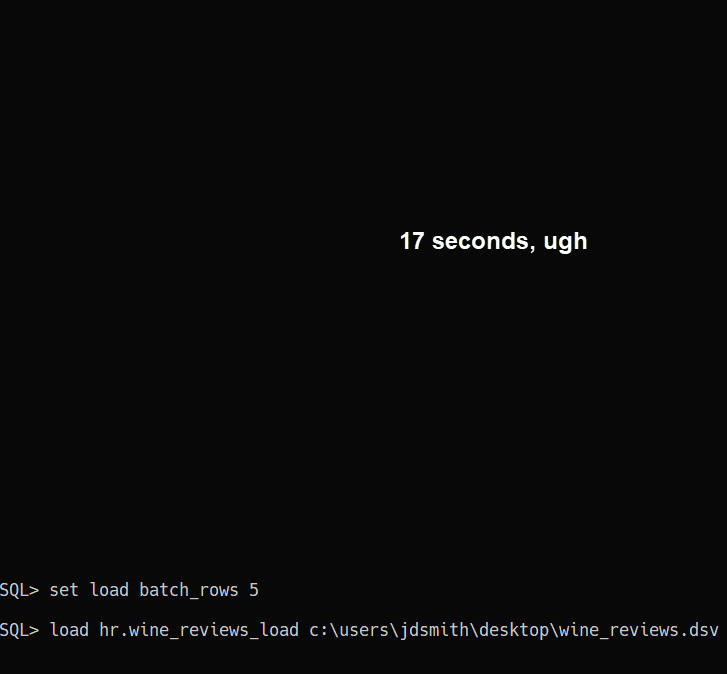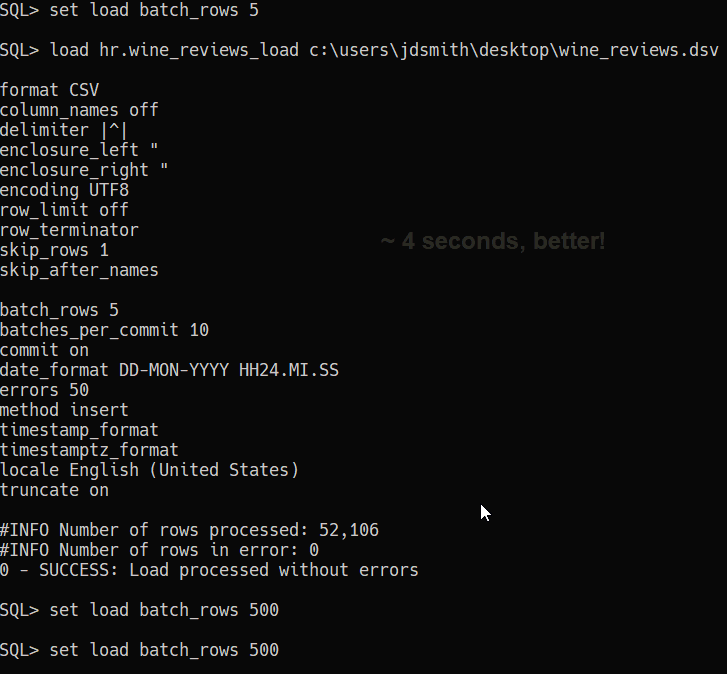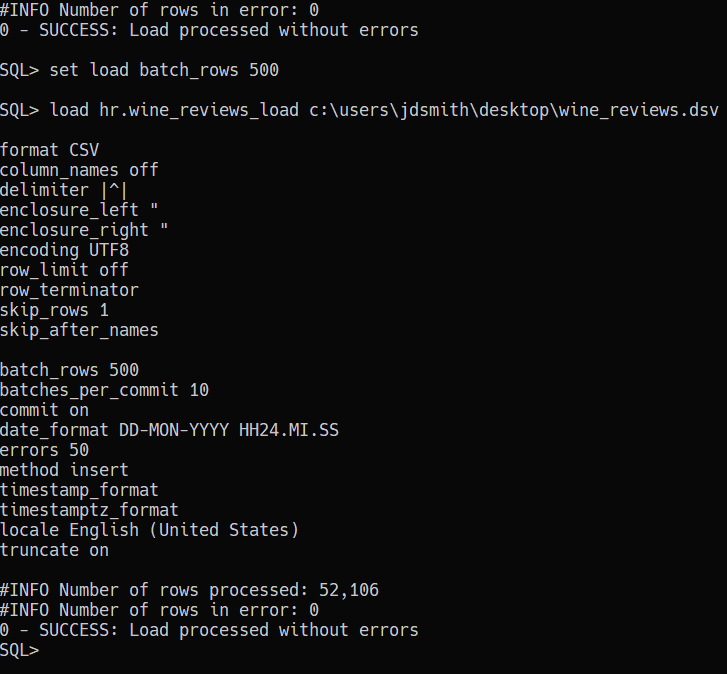
Here’s an example of that in SQL Developer -
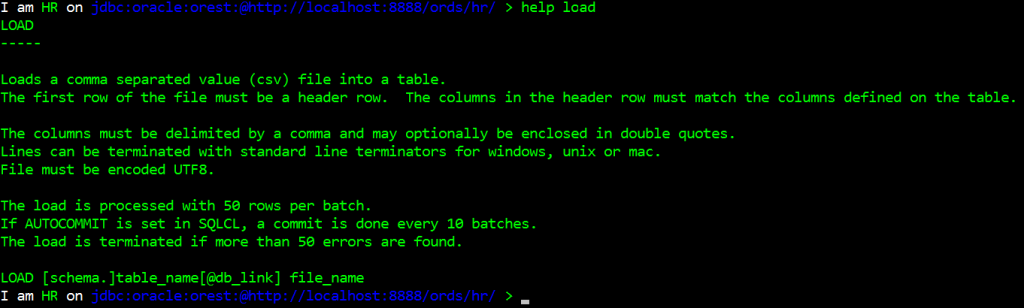
Quick ResultSet Exports as Script Output
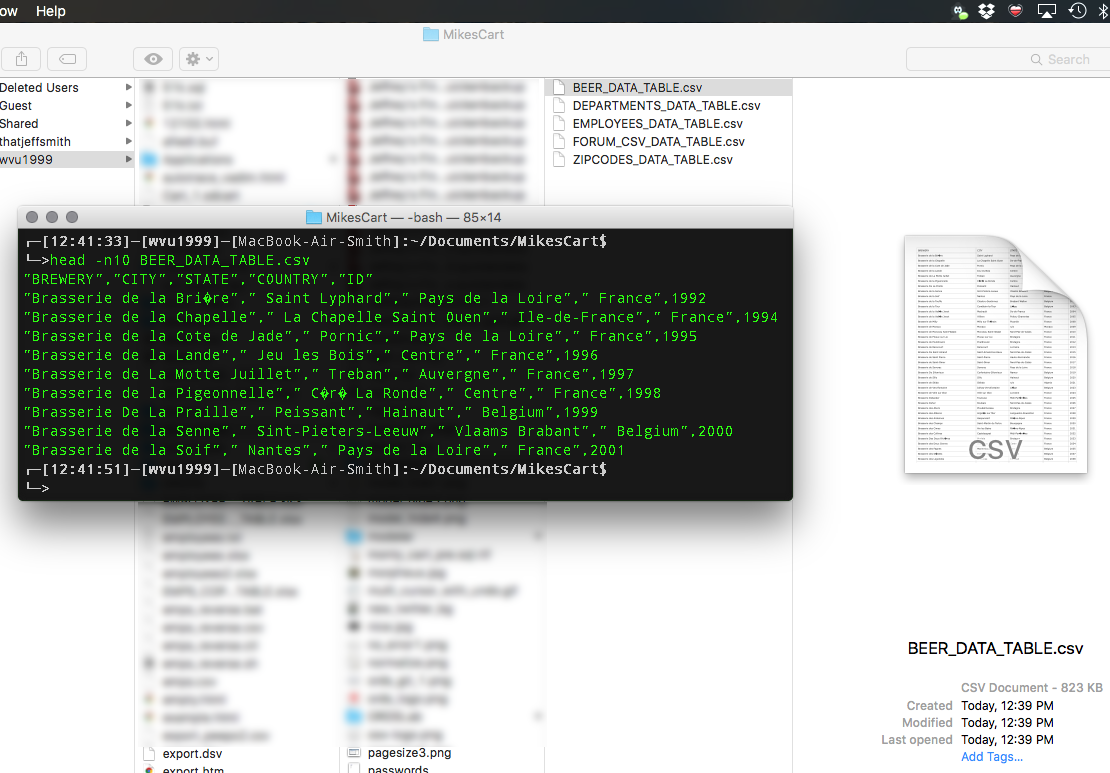
I’m too lazy to hit execute > SaveAs > Open File. I just want to get my delimited text output RIGHT NOW!
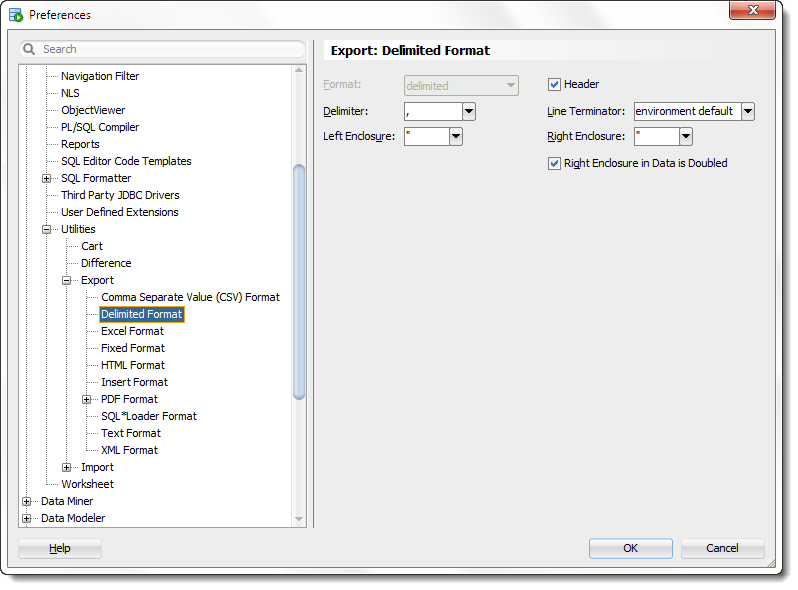
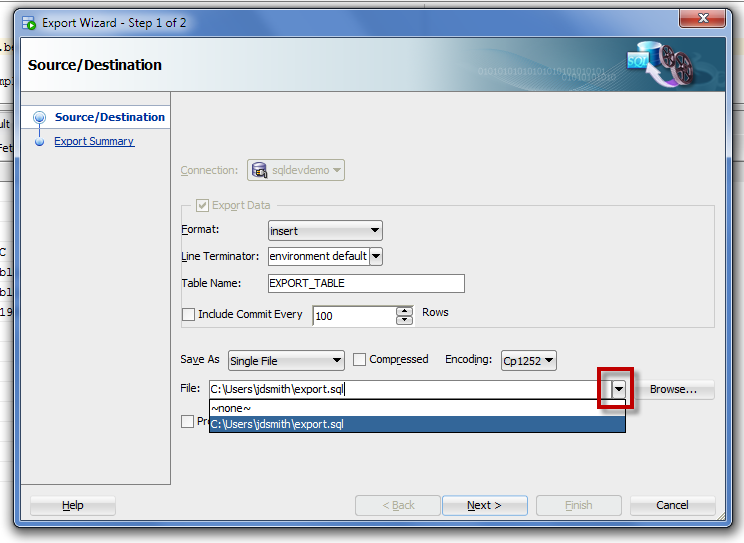
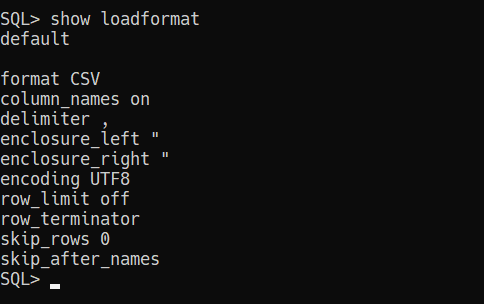
The ‘old’ way -

Our old friend, the Export Dialog
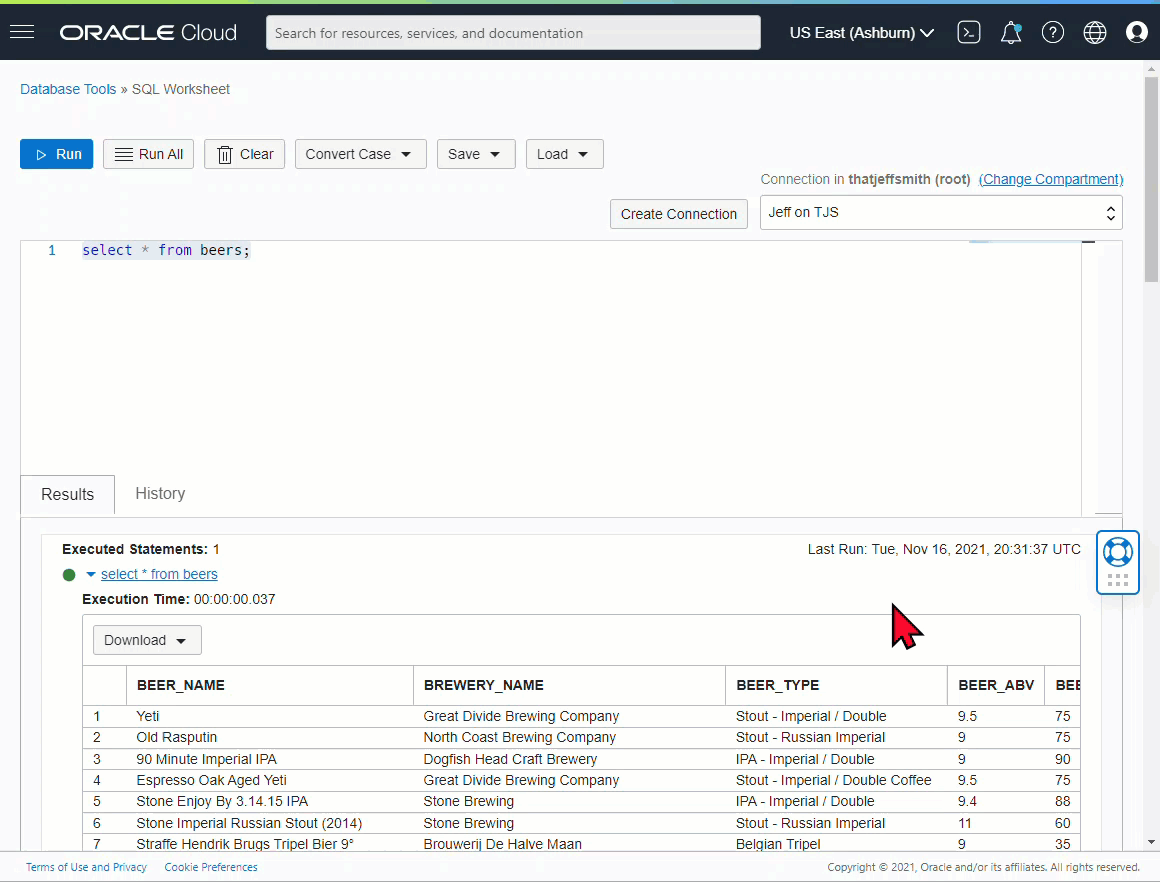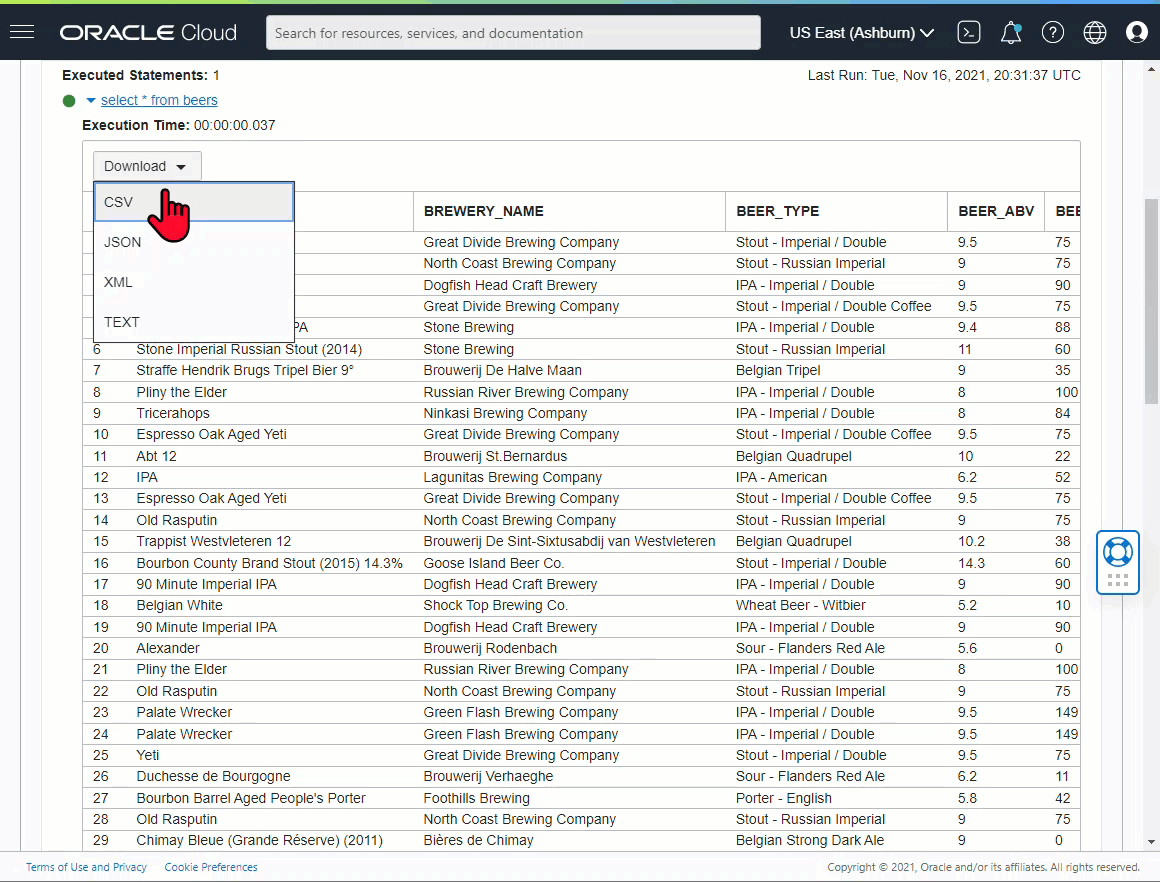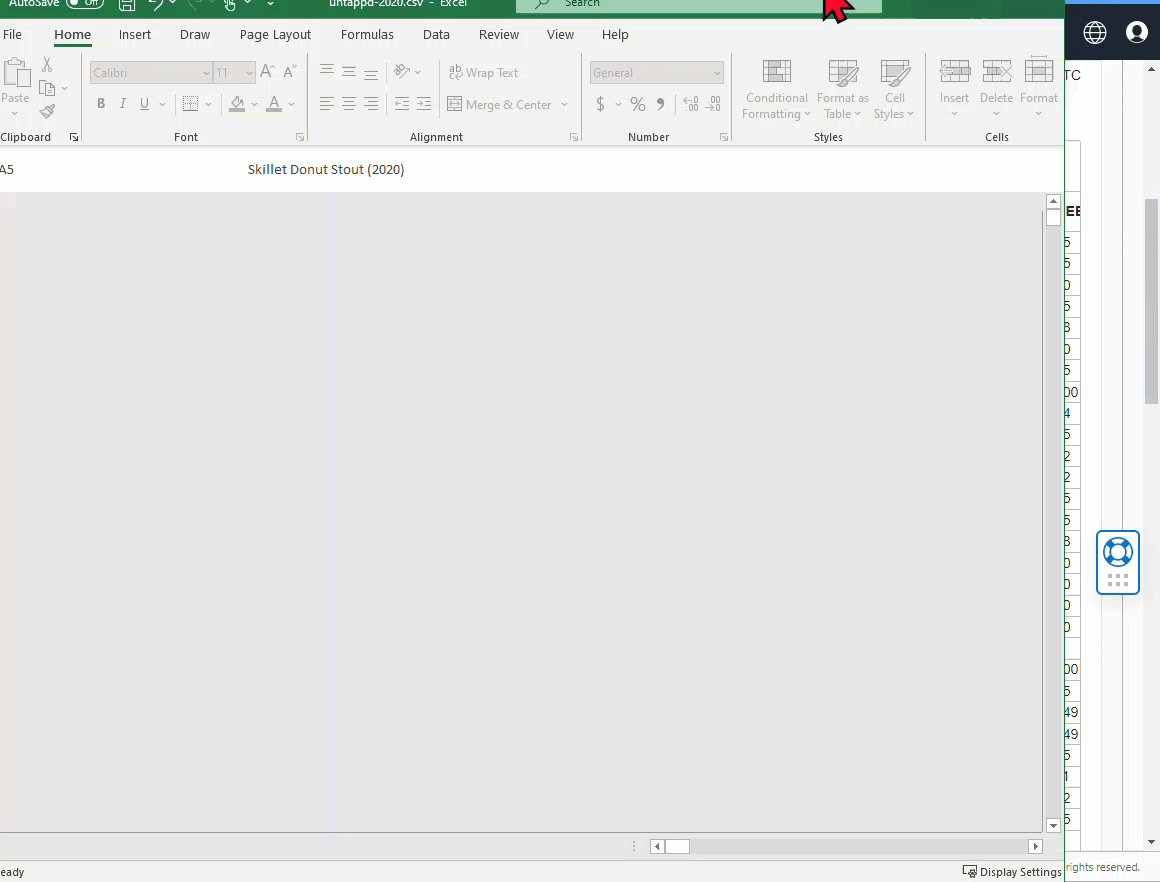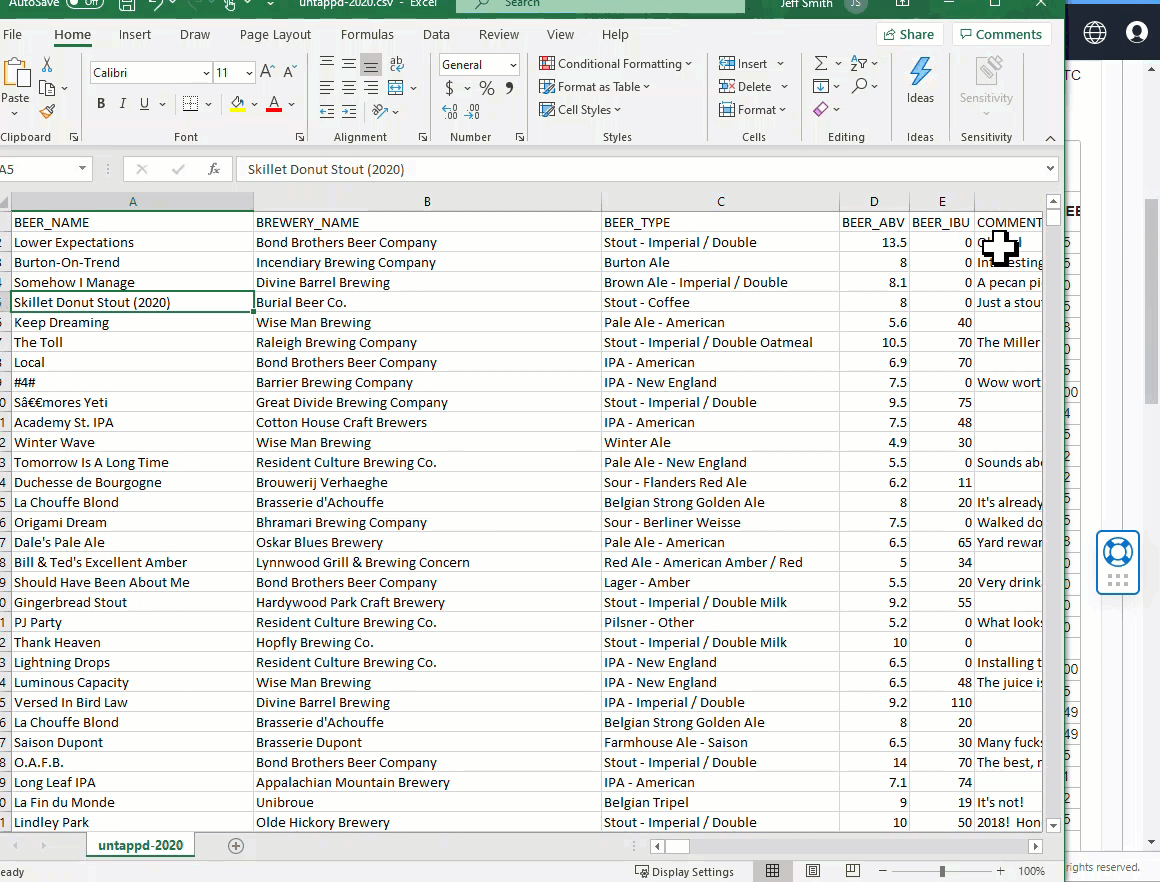
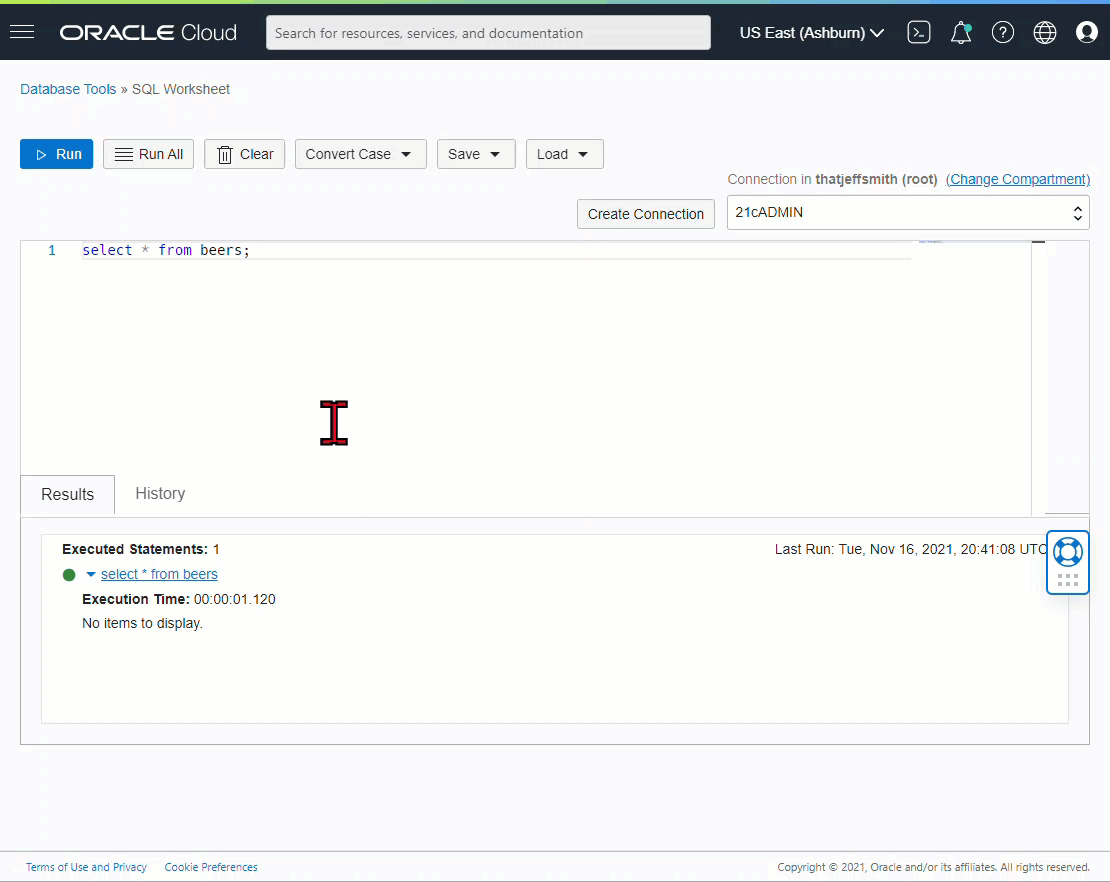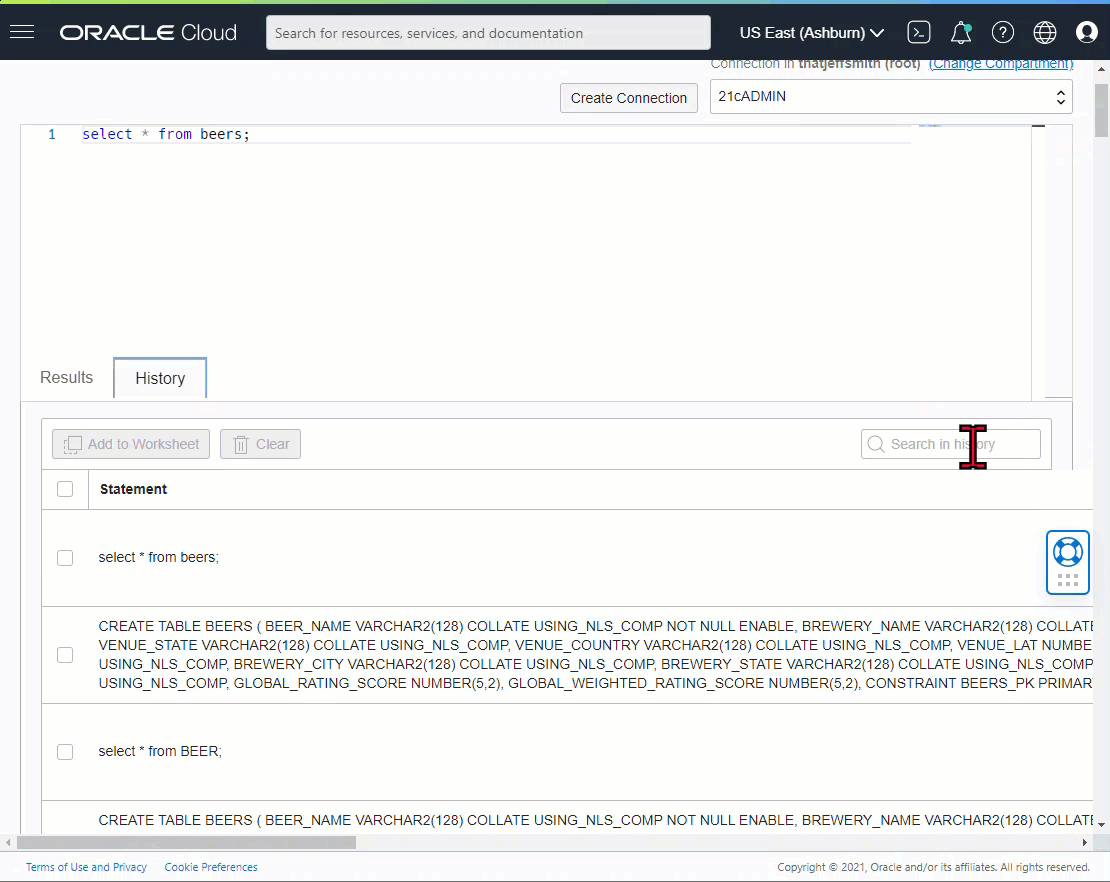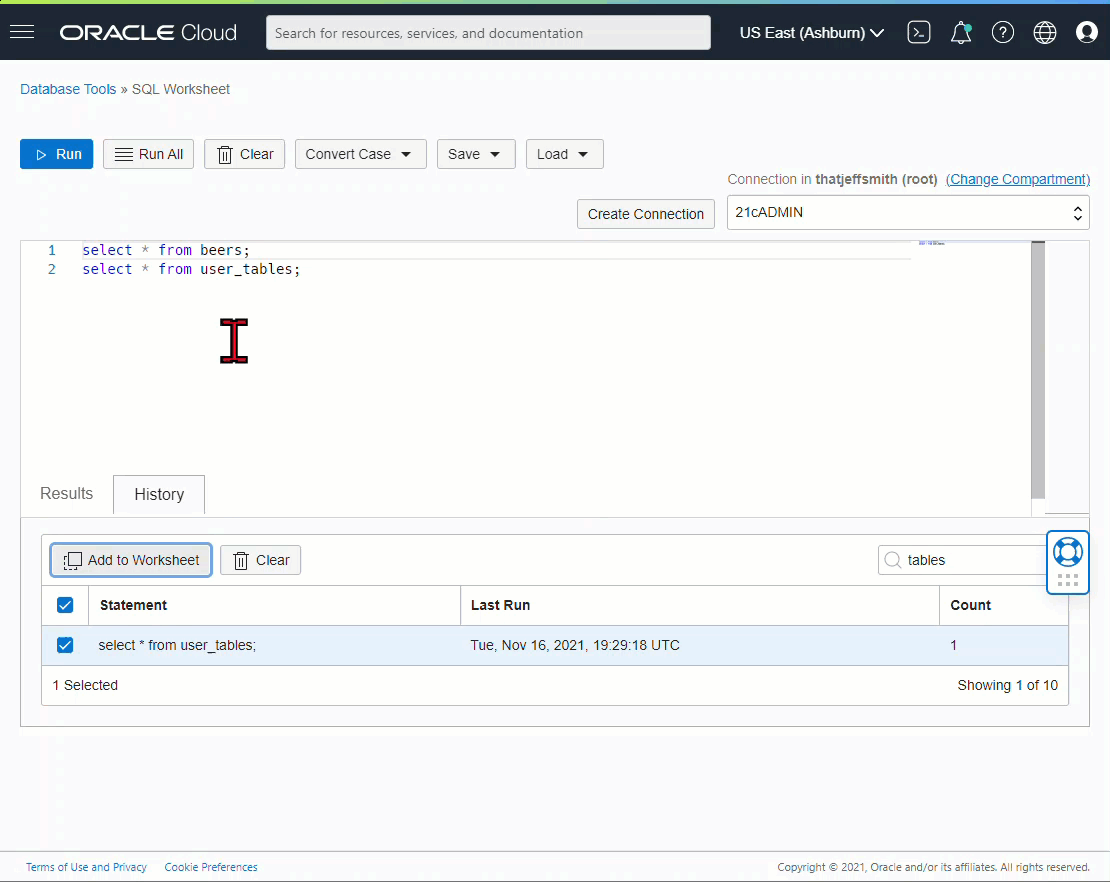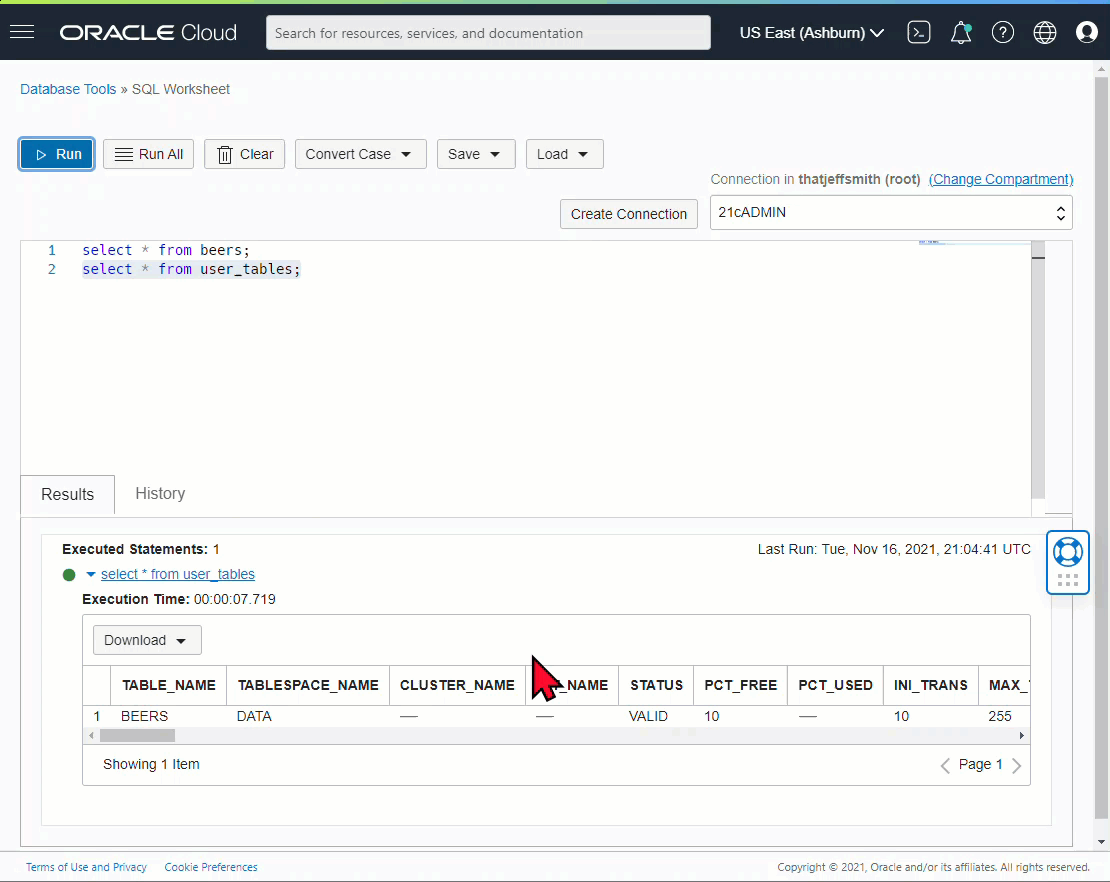
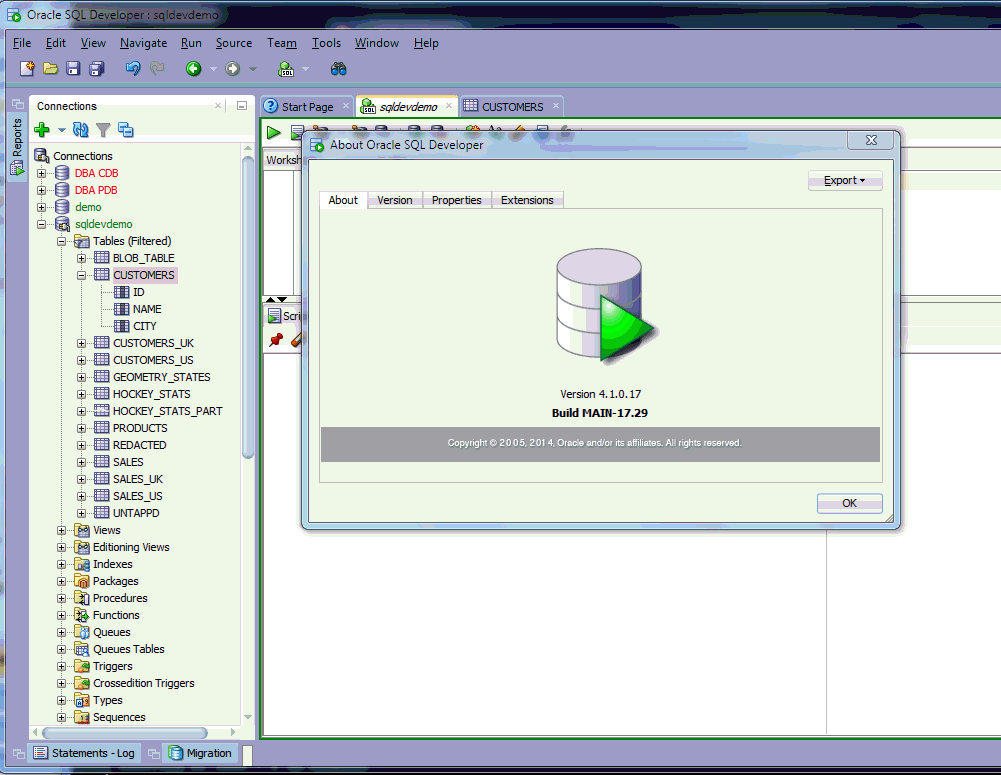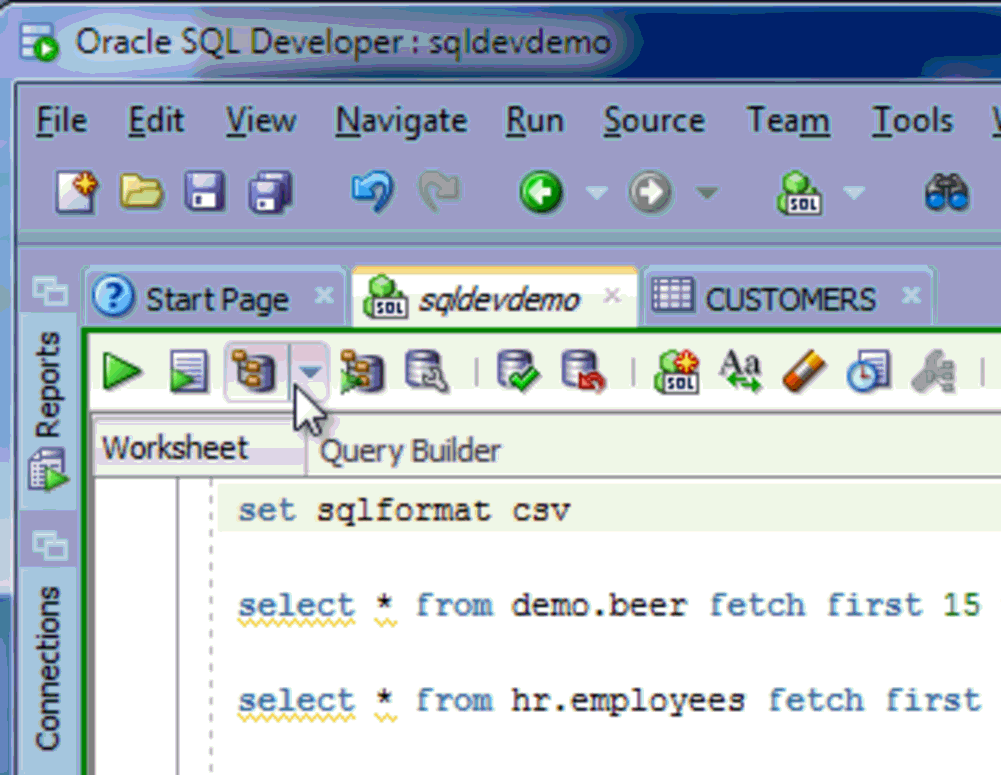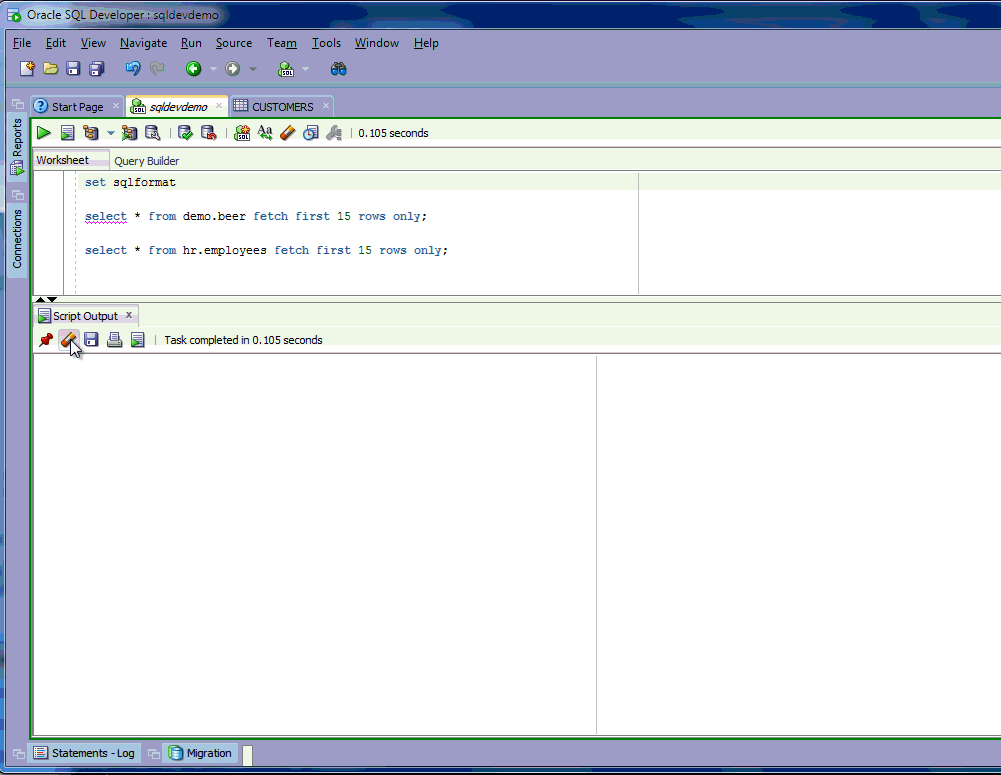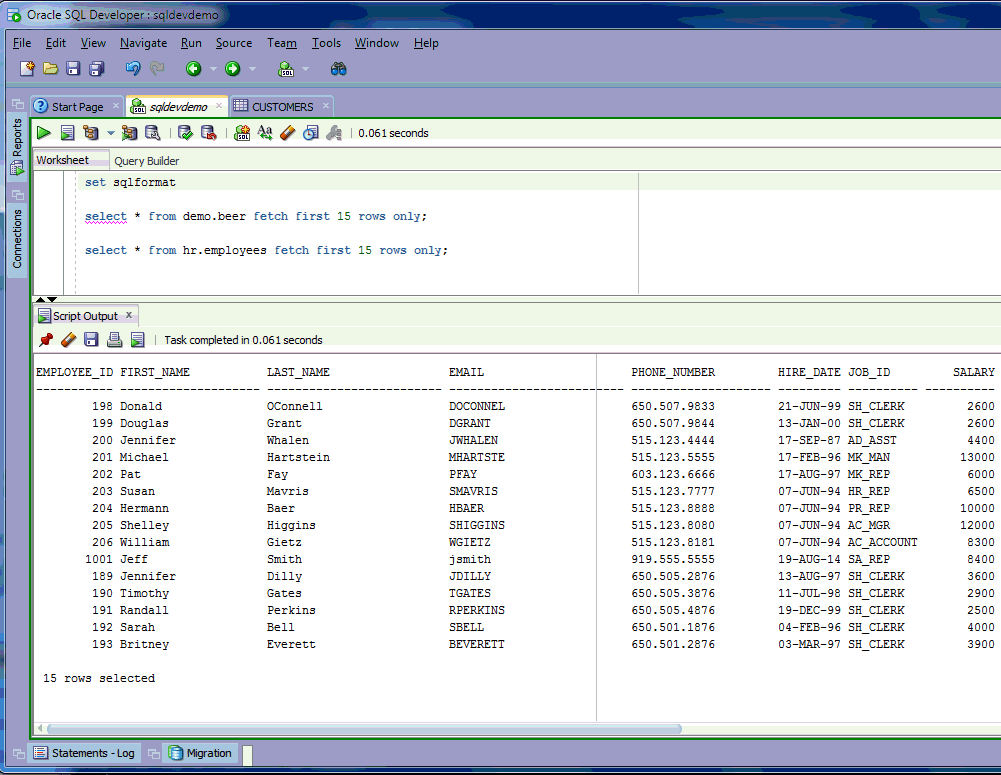
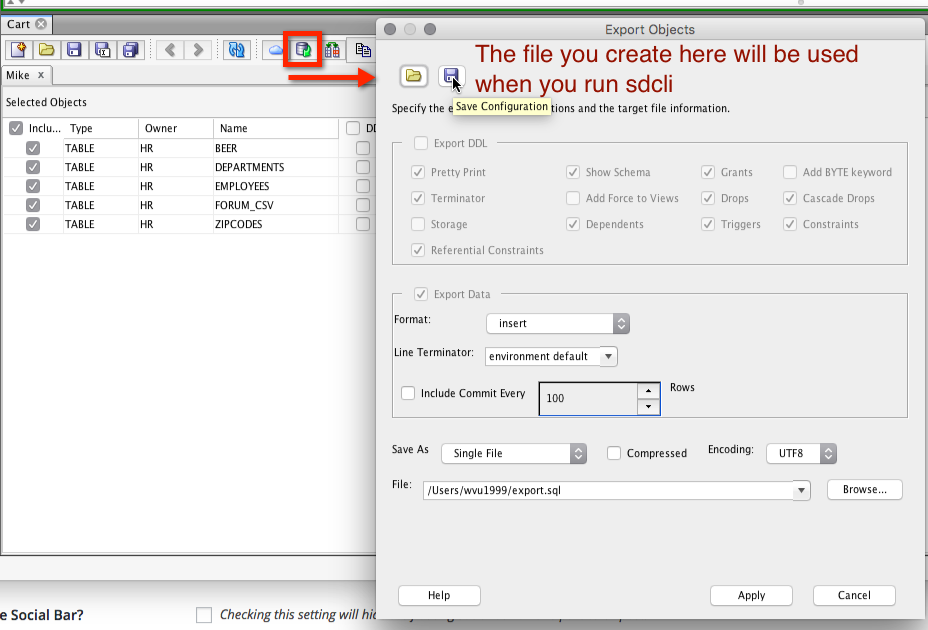
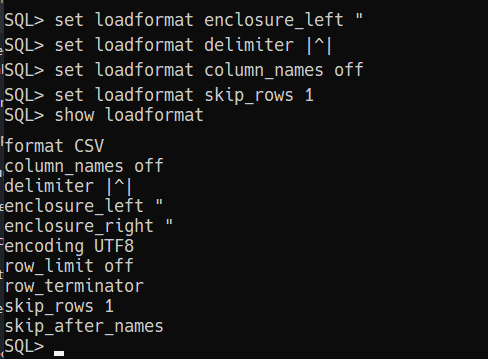
And the ‘new’ way (well, new to me!) -

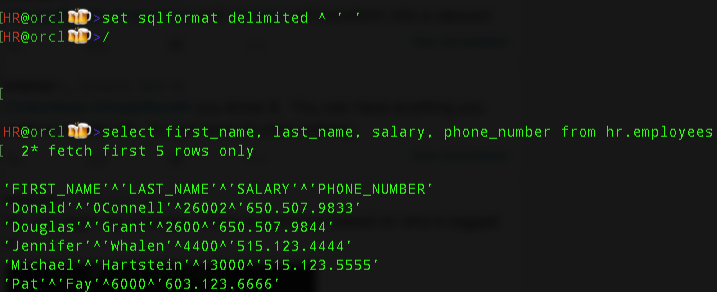
Have the query results pre-formatted in the format of your choice!
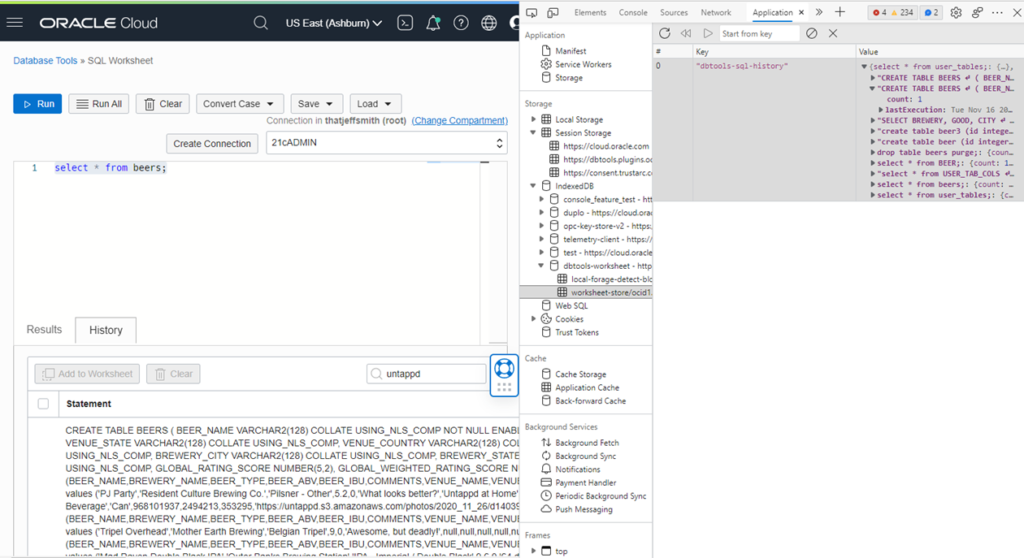
The Code
SELECT /*csv*/ * FROM scott.emp; SELECT /*xml*/ * FROM scott.emp; SELECT /*html*/ * FROM scott.emp; SELECT /*delimited*/ * FROM scott.emp; SELECT /*insert*/ * FROM scott.emp; SELECT /*loader*/ * FROM scott.emp; SELECT /*fixed*/ * FROM scott.emp; SELECT /*text*/ * FROM scott.emp;
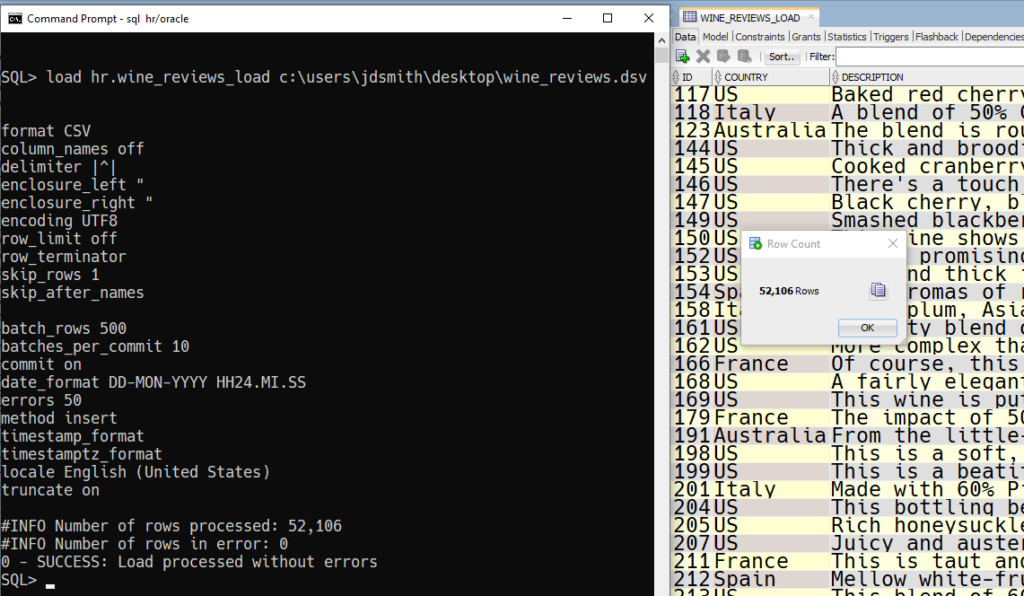
You need to execute your statement(s) as a script using F5 or the 2nd execution button on the worksheet toolbar. You’ll notice the hint name matches the available output types on the Export wizard.
You can try XLSX if you want, but I’m not sure how useful the output will be.
Here’s the raw output from the previous examples in case you’re not sitting at your work desk when you read this (click to expand):
> SELECT /*csv*/ * FROM scott.emp
"EMPNO","ENAME","JOB","MGR","HIREDATE","SAL","COMM","DEPTNO"
7369,"SMITH","CLERK",7902,17-DEC-80 12.00.00,800,,20
7499,"ALLEN","SALESMAN",7698,20-FEB-81 12.00.00,1600,300,30
7521,"WARD","SALESMAN",7698,22-FEB-81 12.00.00,1250,500,30
7566,"JONES","MANAGER",7839,02-APR-81 12.00.00,2975,,20
7654,"MARTIN","SALESMAN",7698,28-SEP-81 12.00.00,1250,1400,30
7698,"BLAKE","MANAGER",7839,01-MAY-81 12.00.00,2850,,30
7782,"CLARK","MANAGER",7839,09-JUN-81 12.00.00,2450,,10
7788,"SCOTT","ANALYST",7566,19-APR-87 12.00.00,3000,,20
7839,"KING","PRESIDENT",,17-NOV-81 12.00.00,5000,,10
7844,"TURNER","SALESMAN",7698,08-SEP-81 12.00.00,1500,0,30
7876,"ADAMS","CLERK",7788,23-MAY-87 12.00.00,1100,,20
7900,"JAMES","CLERK",7698,03-DEC-81 12.00.00,950,,30
7902,"FORD","ANALYST",7566,03-DEC-81 12.00.00,3000,,20
7934,"MILLER","CLERK",7782,23-JAN-82 12.00.00,1300,,10
> SELECT /*xml*/ * FROM scott.emp
<?xml version='1.0' encoding='UTF8' ?>
<RESULTS>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7369]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[SMITH]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[CLERK]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7902]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[17-DEC-80 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[800]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[20]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7499]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[ALLEN]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[SALESMAN]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7698]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[20-FEB-81 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[1600]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[300]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[30]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7521]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[WARD]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[SALESMAN]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7698]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[22-FEB-81 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[1250]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[500]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[30]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7566]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[JONES]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[MANAGER]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7839]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[02-APR-81 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[2975]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[20]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7654]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[MARTIN]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[SALESMAN]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7698]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[28-SEP-81 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[1250]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[1400]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[30]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7698]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[BLAKE]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[MANAGER]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7839]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[01-MAY-81 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[2850]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[30]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7782]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[CLARK]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[MANAGER]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7839]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[09-JUN-81 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[2450]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[10]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7788]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[SCOTT]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[ANALYST]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7566]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[19-APR-87 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[3000]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[20]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7839]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[KING]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[PRESIDENT]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[17-NOV-81 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[5000]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[10]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7844]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[TURNER]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[SALESMAN]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7698]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[08-SEP-81 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[1500]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[0]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[30]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7876]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[ADAMS]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[CLERK]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7788]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[23-MAY-87 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[1100]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[20]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7900]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[JAMES]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[CLERK]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7698]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[03-DEC-81 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[950]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[30]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7902]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[FORD]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[ANALYST]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7566]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[03-DEC-81 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[3000]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[20]]></COLUMN>
</ROW>
<ROW>
<COLUMN NAME="EMPNO"><![CDATA[7934]]></COLUMN>
<COLUMN NAME="ENAME"><![CDATA[MILLER]]></COLUMN>
<COLUMN NAME="JOB"><![CDATA[CLERK]]></COLUMN>
<COLUMN NAME="MGR"><![CDATA[7782]]></COLUMN>
<COLUMN NAME="HIREDATE"><![CDATA[23-JAN-82 12.00.00]]></COLUMN>
<COLUMN NAME="SAL"><![CDATA[1300]]></COLUMN>
<COLUMN NAME="COMM"><![CDATA[]]></COLUMN>
<COLUMN NAME="DEPTNO"><![CDATA[10]]></COLUMN>
</ROW>
</RESULTS>
> SELECT /*html*/ * FROM scott.emp
<html><head>
<meta http-equiv="content-type" content="text/html; charset=UTF8">
<!-- base href="http://apexdev.us.oracle.com:7778/pls/apx11w/" -->
<style type="text/css">
table {
background-color:#F2F2F5;
border-width:1px 1px 0px 1px;
border-color:#C9CBD3;
border-style:solid;
}
td {
color:#000000;
font-family:Tahoma,Arial,Helvetica,Geneva,sans-serif;
font-size:9pt;
background-color:#EAEFF5;
padding:8px;
background-color:#F2F2F5;
border-color:#ffffff #ffffff #cccccc #ffffff;
border-style:solid solid solid solid;
border-width:1px 0px 1px 0px;
}
th {
font-family:Tahoma,Arial,Helvetica,Geneva,sans-serif;
font-size:9pt;
padding:8px;
background-color:#CFE0F1;
border-color:#ffffff #ffffff #cccccc #ffffff;
border-style:solid solid solid none;
border-width:1px 0px 1px 0px;
white-space:nowrap;
}
</style>
<script type="text/javascript">
window.apex_search = {};
apex_search.init = function (){
this.rows = document.getElementById('data').getElementsByTagName('TR');
this.rows_length = apex_search.rows.length;
this.rows_text = [];
for (var i=0;i<apex_search.rows_length;i++){
this.rows_text[i] = (apex_search.rows[i].innerText)?apex_search.rows[i].innerText.toUpperCase():apex_search.rows[i].textContent.toUpperCase();
}
this.time = false;
}
apex_search.lsearch = function(){
this.term = document.getElementById('S').value.toUpperCase();
for(var i=0,row;row = this.rows[i],row_text = this.rows_text[i];i++){
row.style.display = ((row_text.indexOf(this.term) != -1) || this.term === '')?'':'none';
}
this.time = false;
}
apex_search.search = function(e){
var keycode;
if(window.event){keycode = window.event.keyCode;}
else if (e){keycode = e.which;}
else {return false;}
if(keycode == 13){
apex_search.lsearch();
}
else{return false;}
}</script>
</head><body onload="apex_search.init();">
<table border="0" cellpadding="0" cellspacing="0">
<tbody><tr><td><input type="text" size="30" maxlength="1000" value="" id="S" onkeyup="apex_search.search(event);" /><input type="button" value="Search" onclick="apex_search.lsearch();"/>
</td></tr>
</tbody></table>
<br>
<table border="0" cellpadding="0" cellspacing="0">
<tr> <th>EMPNO</th>
<th>ENAME</th>
<th>JOB</th>
<th>MGR</th>
<th>HIREDATE</th>
<th>SAL</th>
<th>COMM</th>
<th>DEPTNO</th>
</tr>
<tbody id="data">
<tr>
<td align="right">7369</td>
<td>SMITH</td>
<td>CLERK</td>
<td align="right">7902</td>
<td>17-DEC-80 12.00.00</td>
<td align="right">800</td>
<td align="right"> </td>
<td align="right">20</td>
</tr>
<tr>
<td align="right">7499</td>
<td>ALLEN</td>
<td>SALESMAN</td>
<td align="right">7698</td>
<td>20-FEB-81 12.00.00</td>
<td align="right">1600</td>
<td align="right">300</td>
<td align="right">30</td>
</tr>
<tr>
<td align="right">7521</td>
<td>WARD</td>
<td>SALESMAN</td>
<td align="right">7698</td>
<td>22-FEB-81 12.00.00</td>
<td align="right">1250</td>
<td align="right">500</td>
<td align="right">30</td>
</tr>
<tr>
<td align="right">7566</td>
<td>JONES</td>
<td>MANAGER</td>
<td align="right">7839</td>
<td>02-APR-81 12.00.00</td>
<td align="right">2975</td>
<td align="right"> </td>
<td align="right">20</td>
</tr>
<tr>
<td align="right">7654</td>
<td>MARTIN</td>
<td>SALESMAN</td>
<td align="right">7698</td>
<td>28-SEP-81 12.00.00</td>
<td align="right">1250</td>
<td align="right">1400</td>
<td align="right">30</td>
</tr>
<tr>
<td align="right">7698</td>
<td>BLAKE</td>
<td>MANAGER</td>
<td align="right">7839</td>
<td>01-MAY-81 12.00.00</td>
<td align="right">2850</td>
<td align="right"> </td>
<td align="right">30</td>
</tr>
<tr>
<td align="right">7782</td>
<td>CLARK</td>
<td>MANAGER</td>
<td align="right">7839</td>
<td>09-JUN-81 12.00.00</td>
<td align="right">2450</td>
<td align="right"> </td>
<td align="right">10</td>
</tr>
<tr>
<td align="right">7788</td>
<td>SCOTT</td>
<td>ANALYST</td>
<td align="right">7566</td>
<td>19-APR-87 12.00.00</td>
<td align="right">3000</td>
<td align="right"> </td>
<td align="right">20</td>
</tr>
<tr>
<td align="right">7839</td>
<td>KING</td>
<td>PRESIDENT</td>
<td align="right"> </td>
<td>17-NOV-81 12.00.00</td>
<td align="right">5000</td>
<td align="right"> </td>
<td align="right">10</td>
</tr>
<tr>
<td align="right">7844</td>
<td>TURNER</td>
<td>SALESMAN</td>
<td align="right">7698</td>
<td>08-SEP-81 12.00.00</td>
<td align="right">1500</td>
<td align="right">0</td>
<td align="right">30</td>
</tr>
<tr>
<td align="right">7876</td>
<td>ADAMS</td>
<td>CLERK</td>
<td align="right">7788</td>
<td>23-MAY-87 12.00.00</td>
<td align="right">1100</td>
<td align="right"> </td>
<td align="right">20</td>
</tr>
<tr>
<td align="right">7900</td>
<td>JAMES</td>
<td>CLERK</td>
<td align="right">7698</td>
<td>03-DEC-81 12.00.00</td>
<td align="right">950</td>
<td align="right"> </td>
<td align="right">30</td>
</tr>
<tr>
<td align="right">7902</td>
<td>FORD</td>
<td>ANALYST</td>
<td align="right">7566</td>
<td>03-DEC-81 12.00.00</td>
<td align="right">3000</td>
<td align="right"> </td>
<td align="right">20</td>
</tr>
<tr>
<td align="right">7934</td>
<td>MILLER</td>
<td>CLERK</td>
<td align="right">7782</td>
<td>23-JAN-82 12.00.00</td>
<td align="right">1300</td>
<td align="right"> </td>
<td align="right">10</td>
</tr>
</tbody></table><!-- SQL:
null--></body></html>
> SELECT /*delimited*/ * FROM scott.emp
"EMPNO","ENAME","JOB","MGR","HIREDATE","SAL","COMM","DEPTNO"
7369,"SMITH","CLERK",7902,17-DEC-80 12.00.00,800,,20
7499,"ALLEN","SALESMAN",7698,20-FEB-81 12.00.00,1600,300,30
7521,"WARD","SALESMAN",7698,22-FEB-81 12.00.00,1250,500,30
7566,"JONES","MANAGER",7839,02-APR-81 12.00.00,2975,,20
7654,"MARTIN","SALESMAN",7698,28-SEP-81 12.00.00,1250,1400,30
7698,"BLAKE","MANAGER",7839,01-MAY-81 12.00.00,2850,,30
7782,"CLARK","MANAGER",7839,09-JUN-81 12.00.00,2450,,10
7788,"SCOTT","ANALYST",7566,19-APR-87 12.00.00,3000,,20
7839,"KING","PRESIDENT",,17-NOV-81 12.00.00,5000,,10
7844,"TURNER","SALESMAN",7698,08-SEP-81 12.00.00,1500,0,30
7876,"ADAMS","CLERK",7788,23-MAY-87 12.00.00,1100,,20
7900,"JAMES","CLERK",7698,03-DEC-81 12.00.00,950,,30
7902,"FORD","ANALYST",7566,03-DEC-81 12.00.00,3000,,20
7934,"MILLER","CLERK",7782,23-JAN-82 12.00.00,1300,,10
> SELECT /*insert*/ * FROM scott.emp
REM INSERTING into scott.emp
SET DEFINE OFF;
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7369,'SMITH','CLERK',7902,to_date('17-DEC-80 12.00.00','DD-MON-RR HH.MI.SS'),800,null,20);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7499,'ALLEN','SALESMAN',7698,to_date('20-FEB-81 12.00.00','DD-MON-RR HH.MI.SS'),1600,300,30);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7521,'WARD','SALESMAN',7698,to_date('22-FEB-81 12.00.00','DD-MON-RR HH.MI.SS'),1250,500,30);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7566,'JONES','MANAGER',7839,to_date('02-APR-81 12.00.00','DD-MON-RR HH.MI.SS'),2975,null,20);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7654,'MARTIN','SALESMAN',7698,to_date('28-SEP-81 12.00.00','DD-MON-RR HH.MI.SS'),1250,1400,30);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7698,'BLAKE','MANAGER',7839,to_date('01-MAY-81 12.00.00','DD-MON-RR HH.MI.SS'),2850,null,30);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7782,'CLARK','MANAGER',7839,to_date('09-JUN-81 12.00.00','DD-MON-RR HH.MI.SS'),2450,null,10);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7788,'SCOTT','ANALYST',7566,to_date('19-APR-87 12.00.00','DD-MON-RR HH.MI.SS'),3000,null,20);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7839,'KING','PRESIDENT',null,to_date('17-NOV-81 12.00.00','DD-MON-RR HH.MI.SS'),5000,null,10);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7844,'TURNER','SALESMAN',7698,to_date('08-SEP-81 12.00.00','DD-MON-RR HH.MI.SS'),1500,0,30);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7876,'ADAMS','CLERK',7788,to_date('23-MAY-87 12.00.00','DD-MON-RR HH.MI.SS'),1100,null,20);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7900,'JAMES','CLERK',7698,to_date('03-DEC-81 12.00.00','DD-MON-RR HH.MI.SS'),950,null,30);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7902,'FORD','ANALYST',7566,to_date('03-DEC-81 12.00.00','DD-MON-RR HH.MI.SS'),3000,null,20);
Insert into scott.emp (EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO) values (7934,'MILLER','CLERK',7782,to_date('23-JAN-82 12.00.00','DD-MON-RR HH.MI.SS'),1300,null,10);
> SELECT /*loader*/ * FROM scott.emp
7369|"SMITH"|"CLERK"|7902|17-DEC-80 12.00.00|800||20|
7499|"ALLEN"|"SALESMAN"|7698|20-FEB-81 12.00.00|1600|300|30|
7521|"WARD"|"SALESMAN"|7698|22-FEB-81 12.00.00|1250|500|30|
7566|"JONES"|"MANAGER"|7839|02-APR-81 12.00.00|2975||20|
7654|"MARTIN"|"SALESMAN"|7698|28-SEP-81 12.00.00|1250|1400|30|
7698|"BLAKE"|"MANAGER"|7839|01-MAY-81 12.00.00|2850||30|
7782|"CLARK"|"MANAGER"|7839|09-JUN-81 12.00.00|2450||10|
7788|"SCOTT"|"ANALYST"|7566|19-APR-87 12.00.00|3000||20|
7839|"KING"|"PRESIDENT"||17-NOV-81 12.00.00|5000||10|
7844|"TURNER"|"SALESMAN"|7698|08-SEP-81 12.00.00|1500|0|30|
7876|"ADAMS"|"CLERK"|7788|23-MAY-87 12.00.00|1100||20|
7900|"JAMES"|"CLERK"|7698|03-DEC-81 12.00.00|950||30|
7902|"FORD"|"ANALYST"|7566|03-DEC-81 12.00.00|3000||20|
7934|"MILLER"|"CLERK"|7782|23-JAN-82 12.00.00|1300||10|
> SELECT /*fixed*/ * FROM scott.emp
"EMPNO" "ENAME" "JOB" "MGR" "HIREDATE" "SAL" "COMM" "DEPTNO"
"7369" "SMITH" "CLERK" "7902" "17-DEC-80 12.00.00" "800" "" "20"
"7499" "ALLEN" "SALESMAN" "7698" "20-FEB-81 12.00.00" "1600" "300" "30"
"7521" "WARD" "SALESMAN" "7698" "22-FEB-81 12.00.00" "1250" "500" "30"
"7566" "JONES" "MANAGER" "7839" "02-APR-81 12.00.00" "2975" "" "20"
"7654" "MARTIN" "SALESMAN" "7698" "28-SEP-81 12.00.00" "1250" "1400" "30"
"7698" "BLAKE" "MANAGER" "7839" "01-MAY-81 12.00.00" "2850" "" "30"
"7782" "CLARK" "MANAGER" "7839" "09-JUN-81 12.00.00" "2450" "" "10"
"7788" "SCOTT" "ANALYST" "7566" "19-APR-87 12.00.00" "3000" "" "20"
"7839" "KING" "PRESIDENT" "" "17-NOV-81 12.00.00" "5000" "" "10"
"7844" "TURNER" "SALESMAN" "7698" "08-SEP-81 12.00.00" "1500" "0" "30"
"7876" "ADAMS" "CLERK" "7788" "23-MAY-87 12.00.00" "1100" "" "20"
"7900" "JAMES" "CLERK" "7698" "03-DEC-81 12.00.00" "950" "" "30"
"7902" "FORD" "ANALYST" "7566" "03-DEC-81 12.00.00" "3000" "" "20"
"7934" "MILLER" "CLERK" "7782" "23-JAN-82 12.00.00" "1300" "" "10"
> SELECT /*text*/ * FROM scott.emp
"EMPNO"null"ENAME"null"JOB"null"MGR"null"HIREDATE"null"SAL"null"COMM"null"DEPTNO"
7369null"SMITH"null"CLERK"null7902null17-DEC-80 12.00.00null800nullnull20
7499null"ALLEN"null"SALESMAN"null7698null20-FEB-81 12.00.00null1600null300null30
7521null"WARD"null"SALESMAN"null7698null22-FEB-81 12.00.00null1250null500null30
7566null"JONES"null"MANAGER"null7839null02-APR-81 12.00.00null2975nullnull20
7654null"MARTIN"null"SALESMAN"null7698null28-SEP-81 12.00.00null1250null1400null30
7698null"BLAKE"null"MANAGER"null7839null01-MAY-81 12.00.00null2850nullnull30
7782null"CLARK"null"MANAGER"null7839null09-JUN-81 12.00.00null2450nullnull10
7788null"SCOTT"null"ANALYST"null7566null19-APR-87 12.00.00null3000nullnull20
7839null"KING"null"PRESIDENT"nullnull17-NOV-81 12.00.00null5000nullnull10
7844null"TURNER"null"SALESMAN"null7698null08-SEP-81 12.00.00null1500null0null30
7876null"ADAMS"null"CLERK"null7788null23-MAY-87 12.00.00null1100nullnull20
7900null"JAMES"null"CLERK"null7698null03-DEC-81 12.00.00null950nullnull30
7902null"FORD"null"ANALYST"null7566null03-DEC-81 12.00.00null3000nullnull20
7934null"MILLER"null"CLERK"null7782null23-JAN-82 12.00.00null1300nullnull10
So that was kind of a ‘trick’ – I’m not sure it’s a documented feature, although Kris did talk about it WAAAAAAAY back in 2007.
Now you can just Run > Copy > Paste!
 #TonguePlantedFIRMLYInCheek
#TonguePlantedFIRMLYInCheek 

































 (@thatjeffsmith)
(@thatjeffsmith)